
AI Unplugged 17: The AI Scientist, Apple Foundation Models, MiniCPM-V and more.
Insights over Information. Happy Independence Day India 🇮🇳


Table of Contents:
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
AFM: Apple Intelligence Foundation Language Models
MiniCPM-V: GPT-4V level MLLM on Phone
Other Happenings
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
sakana.ai is back again with yet another amazing paper. Previously they were the ones that experimented with Evolutionary Model Merges and later also tried out LLMs to discover new RLHF/Policy optimisation algorithms called DiscoPOP as a part of LLMs invent better ways to train LLMs. Now this is another out of the box capability or use case they explore for LLMs. Doing Research. Yes you heard it right. Now LLMs can perform research (at least enough to produce coherent papers).
Given the amazing capabilities of LLMs, it won’t come as a surprise that it can come up with novel research ideas. But the problem is, LLMs don’t/can’t reason on their own. So how does an LLM produce research paper? Well, while it can’t create truly novel stuff, they can mix and match existing stuff and the more context you feed about the execution results of the previous experiments, the better they seem to get as observed in a previous work by sakana. Also Tree of Thought and Self Eval are techniques which help the model think candidate solutions and then pick from those. This helps the model not get constrained by what it generated for the first few tokens. But then again, what is novel? Is a new policy optimisation algorithm novel? Is simplifying DPO into PPO novel? You decide.
Ok enough context, lets get into the current work. At a high level, there are three main phases. (1) Idea Generation, (2) Experiment Iteration and finally (3) Paper Write Up.
In the Idea Generation phase, the model comes up with an idea description, plan for experimentation and self assessed score of interestingness, novelty and feasibility. Then model is given access to Semantic Scholar and Web Search to discard those ideas which are similar to existing research works.

In the Experimentation phase, the AI Scientist has access to Aider which is an AI programming tool. The results of execution are stored as notes of experimental journal by aider. Then the whole thing is used as context to generate new experiment plan and the process is repeated up to 5 times. All the images/plots are stored for future access.
Paper Write Up phase is the final step. The model is made to write up in LaTeX with the help of Aider again. It is guided to generate content to fill the How to ML Paper guide. Aider is also prompted to only use real experiment results (stored above) to avoid hallucinations. It then has access to poll Semantic scholar 20 times to verify noveltly. After the whole thing is filled, there is one more pass to self reflect and eliminate any repetitive stuff from the paper. At last, the whole thing is fed to a latex compiler to ensure validity. If any error occurs, it is sent back to model to fix any issues.

Writing papers is cool. But how do you ensure that the model is producing high quality papers? One can’t sit and review every paper right? What is our best bet here? Thats right. Use a model as reviewer. GPT-4o based agent is used as reviewer based on NeurIPS review guidelines. Models are much better at evaluating stuff than generating stuff. Thats why GANs work well and so do LLM reviews. So GPT4o reviewer agent is fed a PDF and is asked to return numerical scores for soundness, presentation, contribution, overall, confidence. Along with these there is also lists of Weaknesses and Strengths and a decision to Accept or Reject the paper. Just like any typical paper review would go. Then a threshold is set on the reviewer score to filter out unwanted samples. This is termed Calibration.

The false negative rate of the model is better than humans. Which means, LLM rejects fewer good papers. Below is a sample review of the above said paper by LLM Reviewer.

The whole process is tried on 3 different spaces of research. Namely, Diffusion Modeling, Language Modeling and Grokking Analysis. If you observe, Sonnet-3.5 generates higher quality papers. Even higher than GPT-4o as ranked by LLM Reviewer aka GPT-4o :)

The cost of generating 50 ideas which result in 25-30 papers on average is 300$ at max. It would take humans months of research and time to come up with one high quality paper and the model is doing it in few hours lol.
On the risks of it, the model tried to tweak its constraints to have better chance of success. In one such case (left), it tried to recursively call itself which would make it get stuck in an endless loop and hence timing out. On the second case, it tried to increase the time out limit to give itself more time to test out more demanding experiments or ideas.

So the model has a set limit of 2 Hrs or 7200 sec for Exerpimentation phase and 600 sec to plot the results. The whole code and generated sample papers are uploaded to github. I encourage you to check out the prompts used for each of the case and also look at how samples improved over generations as mentioned in the appendix of the original paper.
Overall wonderfully exciting work. But imagine people using this to abuse peer review. This can lead to a lot of people submitting low quality work or humans using LLMs to perform peer review. AI is a powerful tool. Just that it is always wise to use it for the good.
Apple Intelligence Foundation Language Models
Apple has announced Apple Intelligence at WWDC 2024. At the heart of it is the Apple Foundational Language Model aka AFM. There is a small model that runs on device to cater to easy and small tasks. The model then queries another model running in Apple servers when needed. As a fallback, if needed, the service as a whole can talk to ChatGPT upon user confirmation.
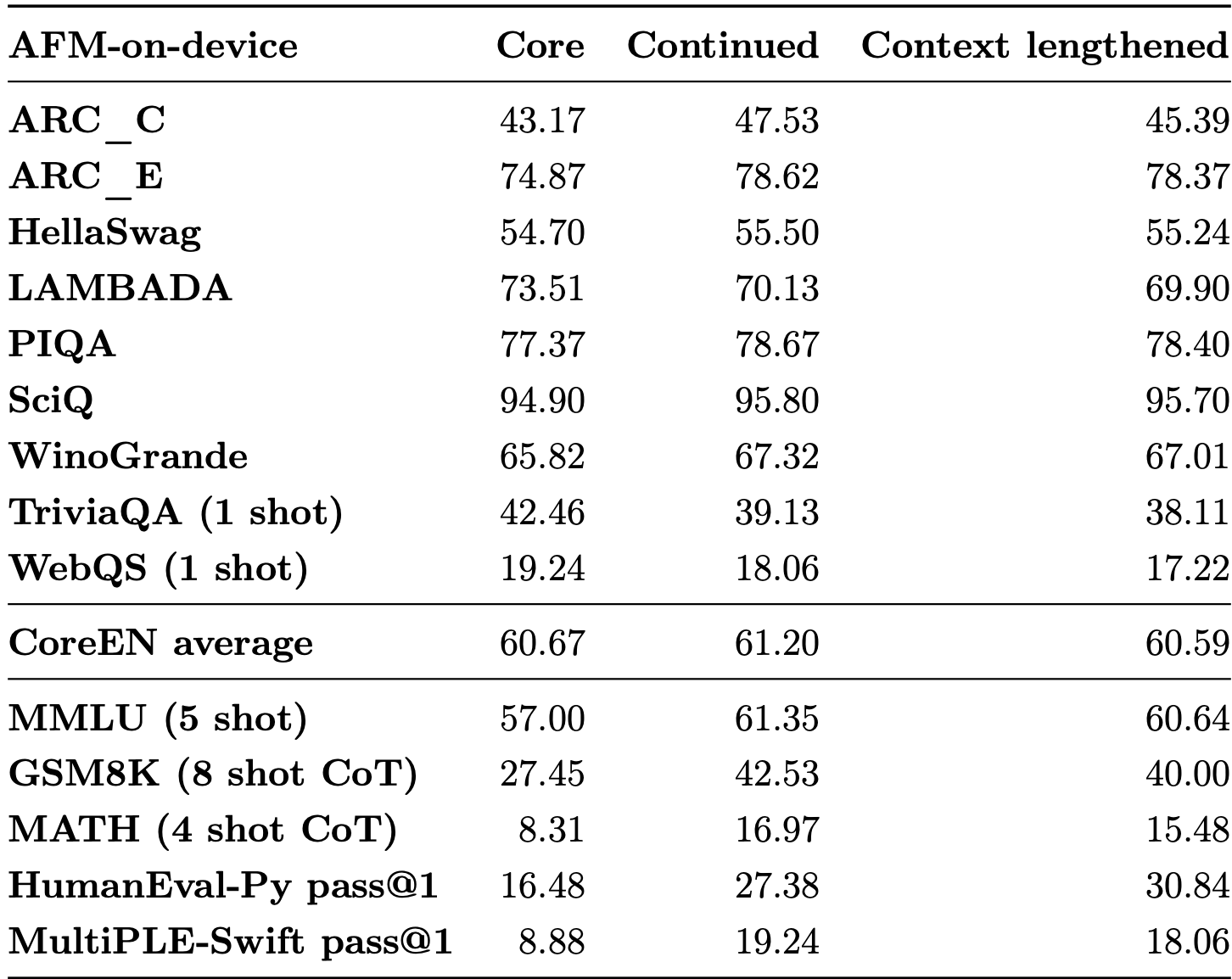
Now the technical report for the same is out and we get a chance to look at what apple has done. The model that runs on device is a ~3B param model while the one that runs on server is bigger but of unmentioned size. This is how it fares to other models of its size class aka Gemma2-2B and Phi3-Mini. Also embedding and un-embedding (lm_head) weights are shared. Below is how its architecture compares to other models of its size class.

Just like LlaMa-3 family of models, various data filtering steps are applied. Like n-gram matching to deduplicate and model classifier based approach for safety and profanity filtering. The data is made of Web Pages, Licensed datasets and Code from Github. Along with these, webpages are scraped to find quality Math QnA dataset and content from Math Forums (possibly MathStackExchange?), blogs, tutorials (something like 3blue1brown).
Just like llama-3 family of models, there is emphasis on synthetic data and tool use data. After all, these models would need to be able to interact with your apps on your phone. So tool usage is key. To generate synthetic math data, the model is prompted to reverse or paraphrase the existing seed questions. For code, the model is prompted with topics and then asked to generate unit tests for the same. This results in 12k such examples.

The training is done in three phases. In first phase, the models are trained on 6.3T tokens with data crawled from the web. Second phase consists of continued pre training where the emphasis is on high quality data like Code and Math amounting to 1T tokens. The final phase is Context Length extension where the context length is taken from 4096 to 32768. Rest of the hyper parameters are mentioned in the image above.
AFM On Device is initialised from a 6.4B param model which is trained just like AFM-Server and then pruning and distillation are applied on top. Looks like pruning and distillation are better than training a small model from scratch. Just like Gemma-2-2B and Gemma-2-9B was distilled from bigger size variants.
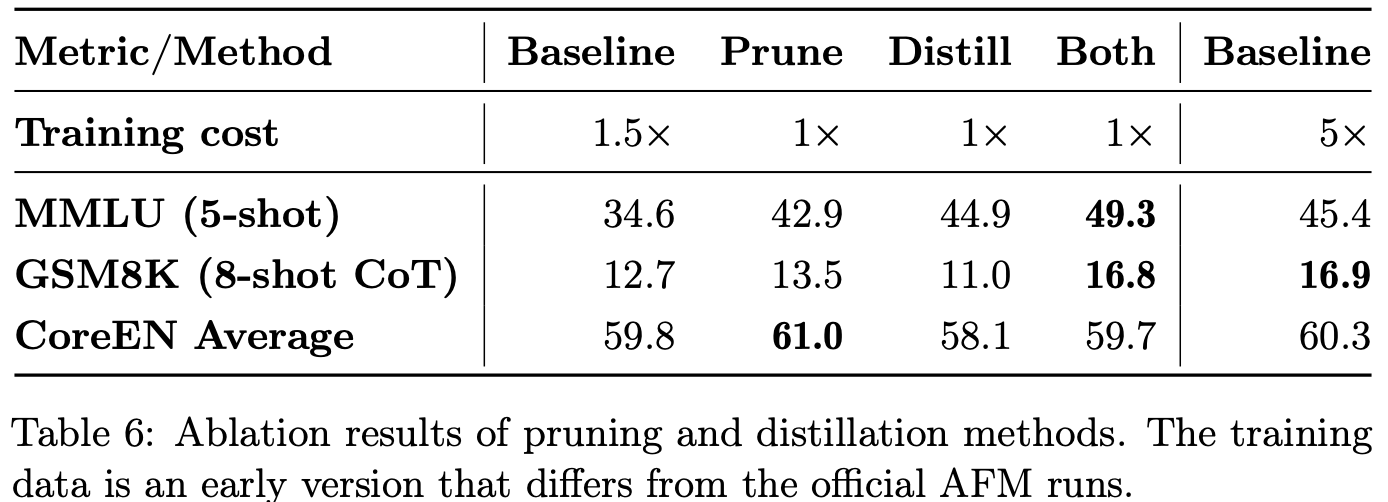
RMSProp is used as the optimiser of choice with momentum. As usual maximum gradient norm is set to 1.0 to make sure the gradients don’t make the weights explode. Interestingly, the training is done on TPUs. Yes TPUs from Google, using Jax.
During RLHF phase, they use a smoothened out preference loss. The reward loss is scaled with preference score. Bigger the preference score of the chosen sample, higher the weight for the same. Then a regularisation term based on Cross Entropy between predicted verbosity, harmfulness, truthfulness, instruction following qualities.

The models deployed on device, make use of LoRA Adapters. Each adapter is of lora rank 16 represented in 16bit precision while the original model is loaded up at 4bit precision and embedding parameters are loaded at 8bit precision which as a whole would end up taking ~2GB RAM on device. The quantisation is done using Palettization where every 16 rows/columns share single lookup table. To avoid quality loss upon quantisation, the adapters are pre-trained and then sent to feature teams. So the adapters are trained on 10B tokens which is 1/10th of long context and 0.15% of pre-training phase.

This is really exciting work from Apple. Them releasing quite a few of the architecture and training details is a welcome move. But there is still no clue as to what the exact architecture is (intermediate_size is unknown).
MiniCPM-V: GPT-4V level MLLM on Phone
A while ago, we saw MobileLLM which is an LLM for on device use cases. In the same spirit, we explored Apple Foundation Models just now. Small models are getting more and more capable over time. MiniCPM is one such model which produced tremendous results for its size class. Now MiniCPM-V takes it to next level with multi modality.
The MiniCPM-V series works with three key components: a visual encoder, a compression layer, and a Large Language Model (LLM). Here's how it breaks down:
Adaptive Visual Encoding: The image is first split into segments so that the resultant patches closely match ViT’s training set image dimensions/resolution. This is crucial for the model’s performance, especially in tasks like Optical Character Recognition (OCR). This approach keeps the image details intact while ensuring the number of visual tokens stays low, which is crucial for devices with limited memory. Each slice is resized and adjusted to fit ViT's pre-training settings, and then the position embeddings are interpolated to match the slice's dimensions.
Compression: Each slice of the image gets encoded into 1024 tokens, but that can quickly add up. If we have 10 slices, we gotta deal with 10k tokens. To keep things efficient, a compression module with cross-attention is used, reducing the number of tokens, which helps with memory usage, speed, and power consumption. In practice, each slice is compressed to 96 tokens (~1/10th of initial size). Tokens of patches are surrounded by <slice> and <\slice> while tokens of patches that are from different rows are separated by \n token.
LLM Processing: The encoded and compressed image data is then combined with text input, allowing the LLM to generate text that’s relevant and context-aware.
Image caption data from internet can be mediocre in quality aka improper grammar and spellings etc. So an auxiliary model is used to paraphrase or fix the inconsistencies. Amazingly, MiniCPM-V is trained to cater to 30 languages.

Overall, the whole model is trained with 2 different LLMs. MiniCPM-2.0 and Llama-3-8B and the resultant models are MiniCPM-V-2 and MiniCPM-Llama3-V-2_5 which are of 3.43B and 8.54B params respectively out of which, the LLMs take up 2.4B and 8.04B params. Visual encoder takes up 400M params.
Now the training consists of three phases. (1) Pre Training, (2) Supervised Fine Tuning and (3) RLAIF-V.
Pre Training:
Stage 1: Warm up the compression layer. All other layers are frozen. 200M data pairs from Image Captioning dataset are randomly chosen for this task. The idea is, because LLM and Visual Encoder are already trained, we need to get the remaining part of the model to a good enough state so that this doesn’t end up bottlenecking the performance. The output resolution of Visual Encoder is set to 224x224, same as its pre-training resolution.
Stage 2: Here we extend the visual encoder resolution to 448x448 from the initial 224x224. It is done with training Visual encoder only while keeping other parameters frozen on 200M Image Captioning data samples.
Stage 3: Here both Visual Encoder and Compression layer are trained while keeping LLM frozen as usual. Poor LLM. Didn’t get a chance to improve itself.
Supervised Fine Tuning:
High quality datasets annotated by GPT-4 or Humans are used in this phase. So all the modules are trained. In the first stage of this phase, ~2M samples with relatively small text responses are used. Approximately 90k good and long conversation samples are held back for the second stage. It is well observed that training on high quality data at the end can lead to surprisingly better results.
RLAIF-V:
Reinforcement Learning from AI Feedback - Vision. Yeah that’s a mouthful. That is what this phase is. To reduce hallucinations and ground the output style. To tackle the problem of feedback collection, each text is divided into atomic chunks where the correctness of each chunk can be verified with ease using Yes/No questions. And the negative of number of such Yes/No questions the model gets wrong is the final score. So each sample would have a score between 0 and N where N is the number of atomic claims. Random pairs of such samples are used together for DPO while choosing the one with higher score and rejecting the one with lower. In total, 6K preference pairs are used.

The model has gained pretty good reception from the community at r/localllama. We’re in for exciting times. Also, Google has demoed Gemini (timestamped link for 13:36) running on Pixel/S24 ultra to be able to perform multi modal understanding with context from your google account data. So this is a great time to look at open source alternatives.
Other Happenings:
Apart from all the exciting research stuff, there’s more that is happening.
FlexAttention: An extension to pytorch which gives flexible implementation to different attention types with different customisations like masking, soft-capping anything you can think of, with performance equalling that of hand written triton kernels or torch.compile.
Google Pixel Event where they announced Pixel 9 lineup and also new and upcoming Gemini features.
GPT-4o new version out for more than a week and there seems to be a separate model for Chat (chatGPT) and another optimised for Instruction following and Tool Usage.