


AI Unplugged 18: MiniTron and Llama-MiniTron, 1.5 Pints, Jamba 1.5 and FocusLLM.
Insights over Information



Table of Contents:
MiniTron: Compressing LLMs via Pruning and Distillation.
1.5-Pints: Pre-Training LLMs in days
Jamba-1.5: Hybrid Transformer Mamba at Scale
FocusLLM: Working around context length limits helping RAG.
MiniTron: Compact Language Models via Pruning and Distillation
TLDR:
Nvidia released compressed models via pruning features and also removing layers of existing LLMs. Those models go through Knowledge Distillation training from the original model. Resultant models outperform pre-trained models of the same size class. Code to be out soon. The models are out at nvidia huggingface.
KL Divergence loss wrt original model logits works great. Removing width (features) is better than removing depth (layers). Can reduce model to half the size while retaining capabilities.When ML models are trained, some weights become more important than the others. For reference, in LlaMA-2-7B, for Q,K,V,O matrices, 50% of eigen values contribute to 90% of information. Also, due to non linearities like ReLU and Silu which output 0 for majority (most negative) inputs, generally speaking, a lot of activations tend to be around zero. So it makes sense to restructure the model to remove those unnecessary weights to decrease the model dimensions. This would help make the inference faster and less resource hungry. This technique is called Pruning.

People have forgotten pruning for a while with LLMs. But now it is rising back. One question to be asked is, how much can you prune? Well given that models now a days come in all sizes, and they generally target known GPU RAM, pruning to half a model’s size becomes a front runner so that we can maximise the GPU RAM utilisation on some other known hardware. Anything more, we run the risk of losing too much information. See above that ~50% of eigen values in QKVO matrices contribute to 90% of information.
Another thing to consider is, due to Residual connections, there is a lot of similarity between outputs of intermediate layers in a big network/LLM. So now, do we also remove a few layers along with reshaping weights in a given layer? Removing layers is generally termed as Depth pruning and restructuring weights in a given layer is called Width pruning.
But just pruning might cause inconsistencies. The model in all its learning life, was accustomed to having all those weights that we pruned. So to let the model adapt, we do some fine tuning on the model to recover some of the lost abilities. Given all the info, how does one decide what to prune. If we can somehow measure the importance of each weight, we can simply remove the ones that are of less importance. But how does one quantify importance?
We discussed how a lot of activations are zero. But to compute activations, one needs inputs aka data. So given a dataset, you calculate on average how much each neuron is activated, how much an attention head are activated. To go from average activation of a single neuron to that of an axis (along which pruning is to be done). So lets say if the k-th feature among given n (original hidden dimension) features is not so important, that row is entirely removed from the network. Below is an example of nvidia/llama-3.1-minitron-4b-width-base which is a 4B parameter model derived from meta-llama/llama-3.1-8B. As you can see the number of layers are unchanged here. But the hidden size is reduced by 25%, from 4096 to 3072 , while the intermediate size is reduced by 35%, from 14336 to 9216 So the QKV matrices which are generally (hidden_dim, hidden_dim) in shape are reduced by 45% and MLP layers which are generally of size (hidden_dim, intermediate_size) are reduced by 52% and reducing the embedding matrix of shape (vocab_size, hidden_dim) by a factor of 25%. This effectively brining down the size of llama-3.1-8B from approximately 8B to approximately 4B (technically 4.5B. but its fine ig)

On the other hand, once can also reduce the number of layers while keeping each layer’s shapes unchanged. This too has been explored and there’s a depth pruned model nvidia/Llama-3.1-Minitron-4B-Depth-Base. Given that original llama-3.1-8B has 32 layers (you can check num_hidden_layers in the above screenshot), Depth Pruning removes 16 layers of least importance. For Depth pruning, importance is calculated by a combination of (1) removing a layer and calculating the perplexity (PPLX) (2) Block Imporance (BI): A function of similarity between input and outputs of that given layer. Note that those layers are removed whose removal contributes to least perplexity and whose input-output similarity is high.
Also note that, the pruning is done iteratively. So given a starting dimension S and target dimension D which T iterations, importance is calculated and at step i, the dimension is reduced from S - i*(S-D)/T to S - (i+1)*(S-D)/T . Basically pruning equally across time steps/iterations.
Given all this info, how does one decide target dimensions? One can simply remove half the layers or remove 30-40% of width to achieve approximately 50% dimensionality reduction. One can also choose to do a combination of the two by pruning say 20% of the hidden features (and intermediate size) alongside pruning say 20% of the layers (which approximately comes up to ~50% pruning). There are ablation studies done to get to a conclusion on this but you’re free to choose.
Now to recover the information that was in the pruned stuff, we do fine tuning. Yay. All in all, the fine tuning is done on <100B tokens. Which is 10-100x smaller than the pre-training corpus of current day LLMs. To make sure we’re not teaching entirely new stuff to the model, to first steer it closer to its previous unpruned state, we do distillation. Distillation is a process where models are trained to mimic the output of some other bigger/better model rather than just the hard labels (ground truth). If you’re keen on learning more about distillation, I highly recommend watching Geoff Hinton’s talk on Knowledge Distillation. Generally when one is distilling knowledge, we use KL Divergence or similar loss functions instead of the usual cross entropy because there is variance in the target labels as well. For those keen on digging deeper on why/how, please watch this video. All in all, the final loss we try to minimise is a combination of Cross Entropy and KL Divergence.

Taking all these into consideration, there are some Best Practices that the paper has outlined. Take a look. Note that (batch=L2, seq=mean) means that to collate the importance of single neuron/feature across batch is done by taking the L2 norm (the standard euclidian distance) and to collate across sequence length dimension, Mean is used.
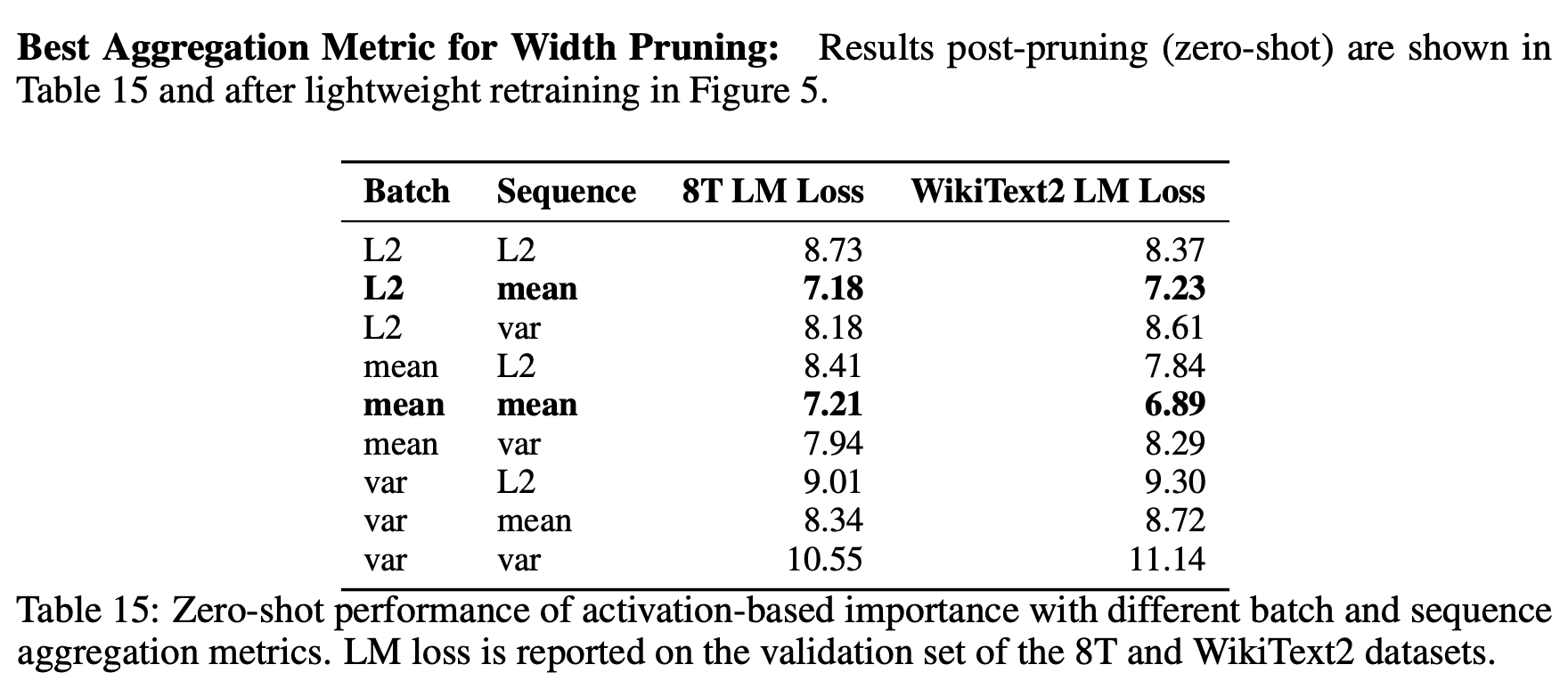
If you closely observe, Width pruning is better than depth pruning. Aka preserve depth as much as you can. This goes well with the observation by Gemma 2 where they compared models of diff shapes but of similar parameter count. The observation there too was Deeper network outperform Wider networks. After all, it is Deep Learning :)

Also along with KL Divergence on output/final logits, it is observed that The final 1-2 layers in a Transformer for LLM are highly specialized and mapping hidden states across (last-2):(last-2) layers for both the student and teacher aka 30-31:14-15 layers’ outputs for 32 and 16 layer networks respectively, achieves the best result.
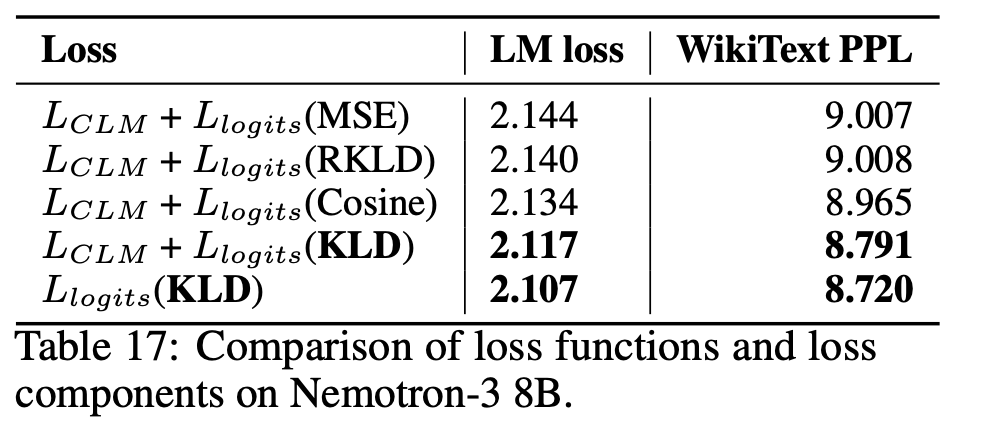
This method provides an easy way to convert a big model into a smaller one. This would open up a lot of possibilities given that pruned models outperform pre-trained small models. There aren’t many 4-5B param models hence people will start shrinking 7-8B param models down as 4-5B is optimal for BF16/FP16 inference on 12GB cards. Similarly, if you have a big model that suits your needs, this provides an alternative to quantisation for making it fit to your needs. In fact, one can probably try quantising the pruned models and see how it goes. The code for the work isn’t available yet, but one of the authors said it’d be out in a couple of weeks. I’ll definitely try compressing models once this is out. So stay tuned for that :)
1.5 Pints: PreTraining LLMs in days
TLDR:
pints.ai trained a 1.5B param model on 115B high quality tokens. The dataset is a mixture of Text Books, Research papers, Parliamentary Debates. The model holds its ground in its size class of <3B params. The model and dataset are available on huggingface. The whole training, from pre-training to RLHF took 9 days on 8xA100 GPUs. This is 100x lower than Llama-2-7b. The model's ideal intended use case is for RAG.
It'd be interesting to see how far we can push this model with techiques like Knowledge Distillation, Softmax capping.To begin with, it is well known that pre training language models takes ages. For reference, Llama-7B took 82432 GPU hours while Llama-2-7B took 184320 GPU hours. So if you have small GPU cluster, it’d take months if not years to pre train any language model. It is also well known that high quality data is much more important than quantity of data. Phi family of models are specifically trained on high quality data like text books. This opens up a void of training a decent sized LLM on small amounts of very very high quality data.
Pints.ai did exactly that. They collated a 57B token worth high quality dataset and use it to pre train a 1.56B parameter model called 1.5-Pints. The whole training took ~9 days on 8xA100s. Which is 1728 GPU hours (Let’s approximate it to 1729 cuz why not. IYKYK). They also open sourced the entire dataset and it is ready to use on HuggingFace. Wonderful.
The model is trained on a total of 115B tokens. Which essentially means the pre training is done for 2 epochs. You might be wondering, if you only train on such niche data, the model would not have knowledge of some facts that are not very bookish. Well thats never a problem. If the model is able to reason well enough, adding appropriate source of information in the context can help the model answer anything. Essentially, hook this model to a RAG pipeline and you have a killer combo.
Given all this, the data curation is quite clearly the most important component of this whole approach. How did pints.ai arrive at such high quality data of such significant volume? The data primarily consists of research papers, copyright-free books, parliamentary debates, and synthetically generated content. Now each of the categories has its own filtering stage.
For creating the books content, each sample is scored on 3 key areas and the highest scoring samples are collected till the dataset token count is met. So essentially no hard limit on score.
Expository (2 points for a yes) - Whether the text explains or substantiates a concept, idea, or an opinion well.
Toxic (-2 points for a yes) - Whether the text contains information that can be considered profanity, sexually inappropriate, racism, discrimination, extremism, or similar.
Clean (1 point for a yes) - Whether the text contains irregular text sequences such as broken words, jumbled up text sequences, or garbled characters, and is generally free from excessive whitespace characters, irrelevant symbols, and any anomalies that may hinder the natural language processing.

All latex in Arxiv dataset is converted to markdown. Wikipedia articles are filtered out if there are <1000 characters in it. For US Public Domain books, first 200 lines are removed to approximately remove the author info, copyright info and contents. For Wikibooks, all the hyperlinks are removed.
Another interesting observation is that models tend to hallucinate at higher sequence lengths, about 95% of context length, while generating synthetic data. If the dataset had >10% hallucinated content, the dataset as a whole is rejected.
Coming to tokenizer, Mistral tokenizer is chosen as it achieves better compression and hence generates 3.61% fewer tokens. Unlike other models, Pints’ tokenizer has special padding token from the pre-training phase itself. It also supports common chat template tokens like <|im_start|>, [INST], <|user|> etc. This is an extension on mistral tokenizer taking the vocab size to 32064.

The hyperparameters chosen are outlined above. One interesting thing is for model relatively smaller than the recent ones (at just 1.5B params), the learning rate is very small aka 4.0x10^-4. For reference, MiniCPM uses a learning rate of 0.01 25x larger. Another interesting thing quoted is GPU utilisation of 99.61%. I’m not entirely sure what parallelisms they used in order to achieve this but this is Huge If True :)

Ok fine, we do all this. But for what you ask? Well the results do look promising. The 1.5B model fares well against every other model which is <3B param. But they choose to exclude MiniCPM-2B which 6.89.

These models are probably not meant for traditional benchmarks. Probably that is one reason why they didn’t even report the numbers. I ran MMLU, Arc and HellaSwag on the same model using Eluether AI’s LM Eval harness. The results are pretty underwhelming. 24.6 on ARC, 37.3 on HellaSwag and 27.02 on MMLU. For comparison, Gemma-2-2B scores 0.46, 0.55 and 0.49 respectively on the same tasks. But this is probably not a fair comparison either as gemma-2-2b was trained on 3T tokens. But then the question is, no one really cares how long the model is trained as long as it fits their use case.
Also this model can be possibly improved upon by techniques like Distillation and Softmax capping and all the other things that have been explored and shown to improve LLMs. But overall, this is a great path to tread. Now imagine scaling the data and/or the model size. The possibilities are quite encouraging. I’m keen for such researches which try something new and is feasible for small people to try, replicate and adopt.
Jamba 1.5: Hybrid Transformer-Mamba Models at Scale
TLDR:
AI21Labs released Jamba-1.5-mini-A14B-57B and Jamba-1.5-large-A98B-398B which are comparable to transformers in terms of performance on end tasks while being efficient inference wise. Jamba-1.5-mini has same architecture as original Jamba while Jamba-1.5-large increases layers, hidden dimension and attention by 2x. Interestingly, Mamba-1-attention hybrid performs better than Mamba-2-attention hybrid.Remember Jamba? Its a combination of Mamba and Transformer from AI21Labs. We’ve covered it extensively how to interpret combination of Mamba and Transformer architecture and how to interpret the parameter count of Mixture of Expert models aka Active parameters vs Total parameters. Do take a look. With that out of the way, lets look at whats new.
With companies training models on larger and larger datasets, it has been a common trend to release models which are mid way through training yet exhibit great capabilities. For example, Gemini released 1.5 series of models. Jamba 1.5 uses similar architecture as of Jamba with increase in size. Similar to the original Jamba, there are 8 blocks in each layer. Among those, there are 7 Attention blocks and 1 Transformer block (based on the finding that this ratio if optimal). Every other layer, Transformer MLP block is replaced by Mixture of Experts.

The model comes in 2 size variants. The smaller one called Jamba-1.5-mini has similar architecture as that of original Jamba while its brother Jamba-1.5-large has 2x the hidden dimension, 2x the mamba rank, 2x the num of attention heads and 2x the number of layers. Thus ending up with 398B parameters off which 94B are active.

For this generation, they also tried replacing Mamba with Mamba-2 but observed that the combo of Mamba-1 and Attention outperforms Mamba-2 attention combo. But why does one need to go the Mamba-Jamba way? Well, the answer is in the curse of transformers. Each inference request is quadratic in time and space in context length. The advantage of SSMs or Mamba is they are linear in terms of context length. Jamba being a hybrid, has some Transformer blocks hence is not as efficient as Mamba but still multiple times better than pure transformers.
To make inferences faster, there’s a new approach undertaken here. The name is ExpertsInt8 quantisation. MoE and MLP weights are quantised to int8, loaded in int8 and then converted to BF16 before multiplication. The whole thing happens inside a fused kernel. So no unnecessary data transfers between GPU DRAM and SRAM. Remember Flash Attention? Surprisingly this is faster than loading the weights in BF16. My hypothesis is, data transfer aka memory bandwidth is a big bottleneck for current GPUs as demonstrated by Flash Attention. So transferring in int8 would reduce the memory by 50%. So transfers are ~50% faster I suppose. The fused kernel hides the de-quantisation delays. This kernel has been contributed to vLLM.
Another interesting thing in the paper is, Activation Loss. It is observed that the activations sometimes reach as high as 4x10^6. This is very very high when rest of the weighs are hovering around 0. Surprisingly, it apparently doesn’t hurt training performance? But this would definitely hurt quantisation (outliers). Hence they add Activation Loss. It is basically Mean Square of the activations.
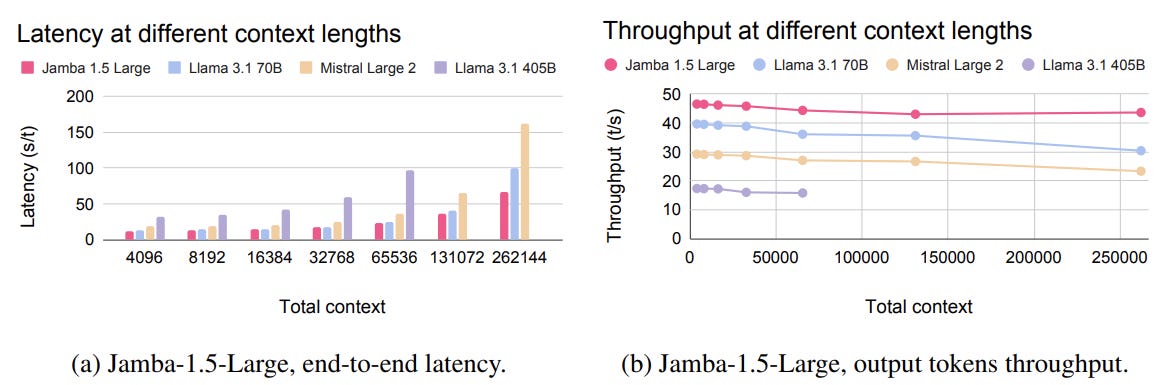
Look at the above figures. Even with 98B active params, which is more than Llama-3.1-70B and also given that it has 398B parameters in total, it is much much faster than the llama counterpart. But one has to also note that you’d need much much more memory to even load the weights of Jamba-1.5-large. So choose your poison I guess?
Also Pre Training on MultiLingual data while Post Training on English only data is good enough. As for results, the models perform quite well relative to other models of similar active parameter count. The only thing is, at similar active param count, you’d need multi fold more memory.

A new benchmark called RULER, a set of 13 synthetic benchmarks to assess the long context capabilities. 8 variants of needle in a haystack which also include multiple needles. 1 variable tracking task to track a chain of variable bindings. 2 aggregation tasks that need to return most frequent words. 2 question answering tasks. One interesting thing is, due to tokenisation, the word count is not a strong suit for these models. There aren’t any individual task wise results but overall, these models seem to hold up well across all these tasks while Transformer counterparts seems to fall off pretty quickly. Somewhere around half the original context window. Note that this observation was also made by Ali from cosine on Latent Space Podcast.

All in all interesting work. I’d have loved to see some comparisons against MoE transformer models. Qwen2-A14B-57B is the closest model to Jamba-1.5-mini. It does trade blows with the said model. However, Jamba-1.5-mini seems to outperform Transformer models significantly on coding benchmark HumanEval and Math benchmark GSM8K. If I have to completely guess, maybe the models are learning better than the transformer counterparts which are probably overfitting? This might be a completely absurd hypothesis but a hypothesis nonetheless :)
Unfortunately there isn’t much info about dataset, data distribution or any training attributes. But exploring alternatives to transformers is something we need to do to probably land up at a hopefully better architecture. More power to you AI21Labs.
FocusLLM: Scaling LLM’s Context by Parallel Decoding
TLDR:
FocusLLM tries to work around the context window length of LLMs for RAG by performing inference with only single chunk in context. Then another decoder is used to collate all the responses into one. The advantage is, it avoids having unnecessary info in the context hence the model doesn't get confused. This method is also memory efficient and can also be comparable in terms of latency on low power GPUs.Increasing the context length of large language models (LLMs) is crucial for tasks like analyzing documents and generating long-form text. However, Traditional models have limitations in handling long texts due to their quadratic complexity. To address these issues, methods like tweaking attention mechanisms and compressing tokens were proposed. Yet, these solutions often result in losing crucial details from earlier sections of the text, which can undermine tasks such as fact-checking and answering questions.
This paper introduces FocusLLM, a solution that manages long texts by using parallel decoding. FocusLLM fine-tunes a decoder-only language model by preserving the original parameters while introducing extra parameters for the Query, Key, and Value matrices at each layer (or can also use LoRA) to aid in training. These additions help aggregate information from different chunks of the text more effectively. Here’s how it works: when presented with a lengthy document and a related question, FocusLLM breaks the document’s tokens into manageable chunks. It then appends the question tokens to each chunk, ensuring that none exceed the model’s context length.
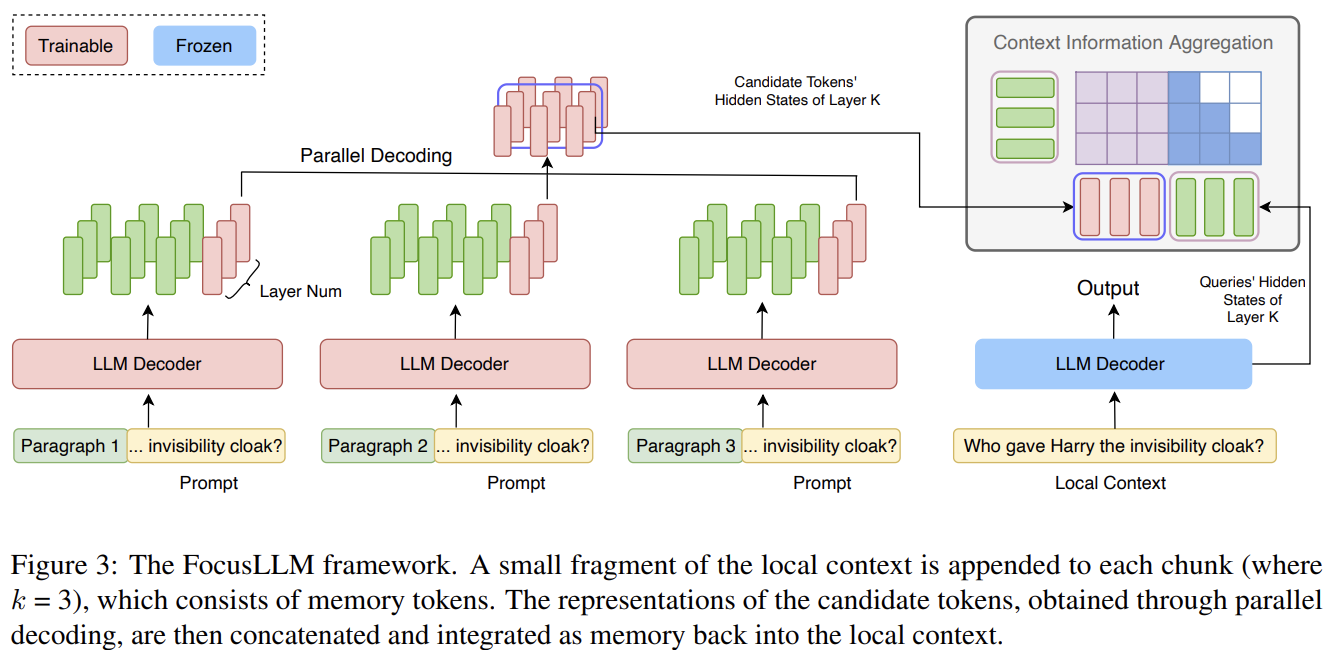
Rather than processing the entire text in one go, FocusLLM decodes each chunk in parallel. This approach involves generating candidate tokens for each chunk and then passing them to another decoder along with the local tokens to produce the final result. By processing chunks in parallel, FocusLLM reduces both time and space complexity significantly. While standard transformers face a quadratic complexity of O(L^2) for sequence length L, FocusLLM cuts this down to O((L/n)^2) per chunk and O(L^2/n) in terms of space complexity, making it far more efficient for very long sequences.
The experiments are conducted on the LLaMA2-7B-Chat model, with an additional 2 billion parameters. The model was trained with two types of loss functions:
Continuation Loss: This loss is defined when the last L tokens of a long document are used as local tokens, while the preceding tokens serve as memory tokens. The purpose of this loss is to train the model's ability to continue generating new tokens that logically follow from the context provided by the memory tokens. Essentially, it focuses on the model's ability to extend or continue a sequence based on the recent context.
Repetition Loss: This loss is defined when the entire long document is used as memory tokens, and then L continuous tokens are randomly selected from this document to act as local tokens. The objective of this loss is to train the model's ability to repeat or reproduce information when it is already available in the context. In other words, it emphasizes the model's ability to generate outputs that accurately reflect or repeat existing information from the memory.

FocusLLM was evaluated on long-context benchmarks with text lengths ranging from 4K to 128K tokens and showed performance comparable to fine-tuned full-attention models while being more resource-efficient. It also maintained stable perplexity at even longer lengths (up to 400K tokens) without the information loss seen in compression-based methods. In comparison with models like StreamingLLM, InfLLM, Activation Beacon, and CEPE on Longbench and ∞-Bench, FocusLLM outperforms them all. It excels in understanding and reasoning over lengthy sequences, whereas other models either struggle with extremely long contexts or incur high computational costs. FocusLLM’s method of processing text in chunks and parallel decoding has proven to be efficient and effective, delivering superior performance while conserving resources.
 | A guest post by
|