


AI Unplugged 6: Jamba, Grok 1.5, Stable Audio 2.0, Octopus v2
Insights over Information

Table of Contents:
Jamba
Grok 1.5
Stable Audio 2.0
Octopus v2
Jamba: The best of both worlds
AI21Labs announced Jamba. Jamba basically is a mixture of Mamba that is powered by State Space Models and Transformers. It tries to leverage the advantages of both to compensate for the drawbacks of the other.
Before getting started, lets have a recap of State Space Models. Below is the architecture of Mamba thanks to this wonderful blog. SSMs try to bridge the gap between Transformers and RNNs. RNNs being purely sequential, cannot be parallelised much while training. Transformers owing to quadratic complexity, struggle at inference for long sequences.

Mamba (SSM) make use of RNNs and parallelise them by pre calculating the matrix multiplications and using prefix sum and to do this, they do away with non linearity. And as the name says, they’re sequential and hence don’t really suffer from the quadratic curses like transformers while inferencing. Also, we talked about Based from Together AI, another transformer alternative few weeks ago. BTW, this blog talks more about transformer alternatives, do give it a read :)
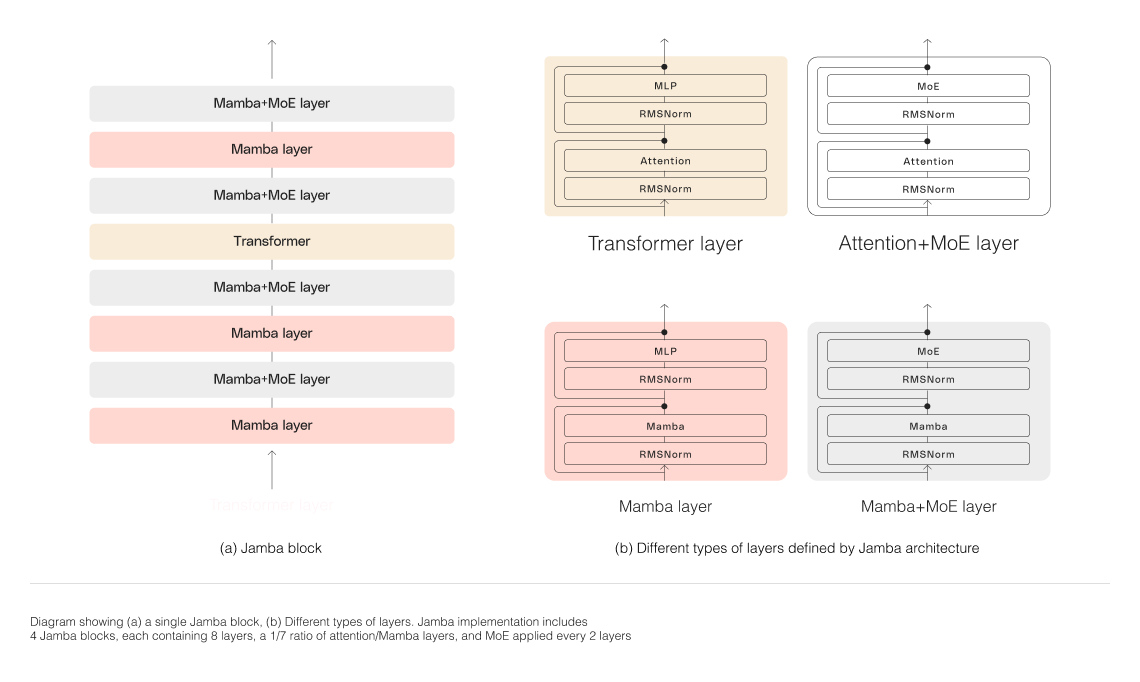
Coming back to Jamba, here’s the architecture diagram of Jamba. It squeezes in transformer layer between Mamba layers. To be exact, one in 8 layers is a transformer or Attention to Mamba ratio is 1:7. And as everything off late, this too is a Mixture of Experts model like DBRX, Mixtral etc. Thanks to being efficient, one can fit 140k context in single GPU while for llama, we can only fit in 16k.
So out of the 52B params, only 12B are active for any inference request, thanks to the MoE architecture. Looking into the code, each Mamba layer has 281477408 params, Transformer layer has 218112000 params and Mamba MoE layer has 18887748416 params. Among these, experts make up for 176160768 * 16 = 2818572288 params and the rest are 105382176 params. So for inference, as there are 2 out of 16 active experts, it’ll use 105382176 + 2818572288 x (2/16) = 457703712 params. There are a total of 32 layers aka 4 Jamba blocks. And the embedding matrix is of shape (65536, 4096) meaning a vocab size of 65536 and hidden dim of 4096. Embedding parameters count hence is 268435456
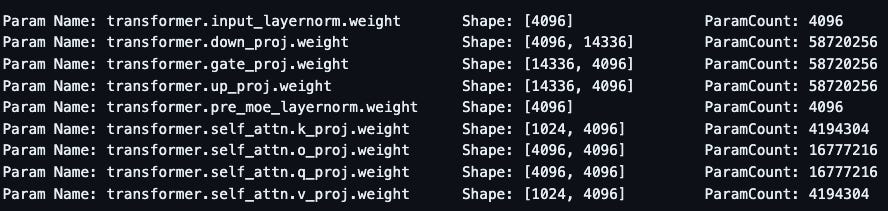
As you see, the hidden dimension of transformer block is set to 4096 and MLP’s internal dimension is 14336.

There are a total of 16 experts and only 2 of them are used while inferencing. While DBRX and Mixtral use 1/4th of the experts, Jamba only uses 1/8th. So in a Jamba block while inference, we go through 3 Mamba layers, 1 transformer layer and 4 Mamba MoE layers working at 1/8th capacity. So total active param count for inference per Jamba block is
And there are 4 such Jamba blocks and embedding parameters while inference. So the total would be 12B as mentioned in the table below.
KV Cache is only for Transformers blocks. Each k and v are of size 4096. There are 4 blocks. So the total KV Size for 256k context at 16 bit would come up to 4 blocks x (1024 +1024) values/block per context x (256K context) x (16 bits per value) = 4GB

Thanks to not being as memory and compute hungry as transformers, we Jamba can fit in bigger batch sizes in single GPU for inference. The difference in throughput only grows larger with higher context windows.
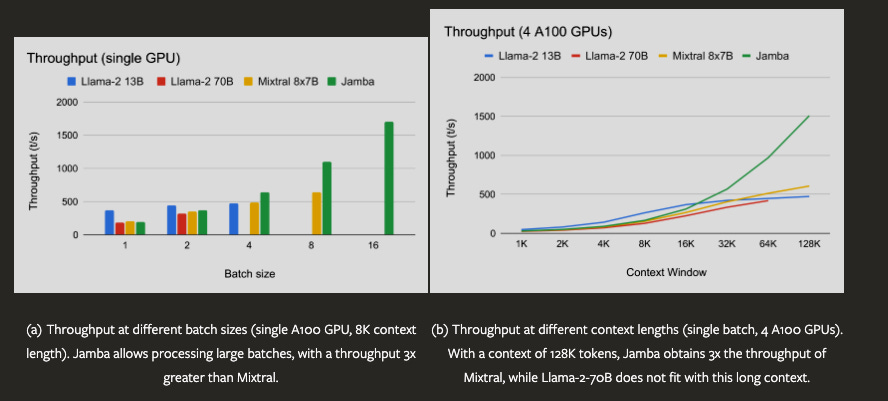

They do compare Jamba to Llama and Mixtral. And it holds its own ground. It performs closely to Mixtral with 56B parameters and 13B active parameters. So replacing Jamba is pretty solid compared to Transformers of equal size. But let’s also look at how it fares against recently released DBRX.

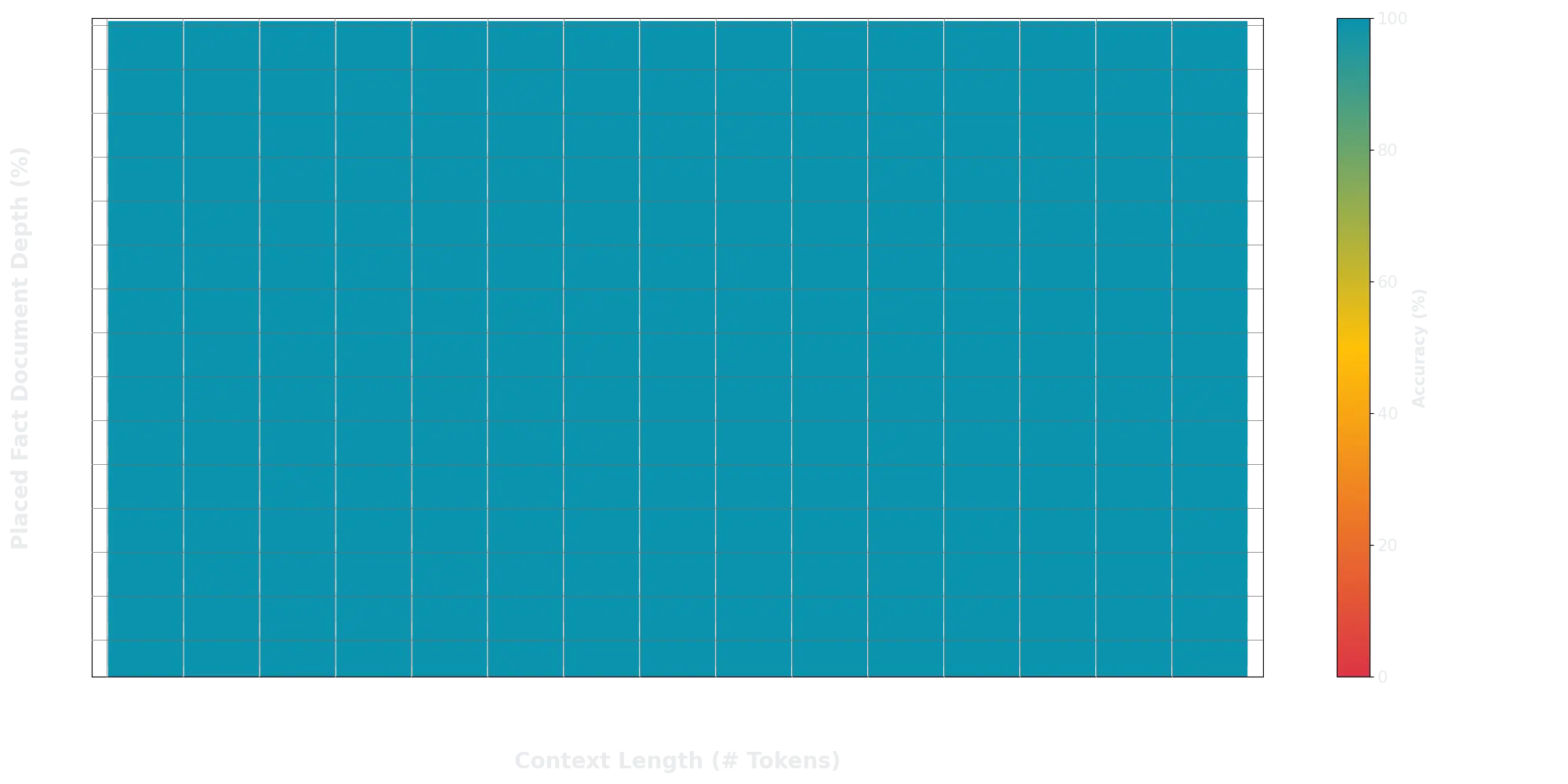
One might argue that these models might not be good at recall. But Jamba does perform extremely well in Needle in a haystack test. It does forget some info from the start of the context if the total text is ~256k length (see yellow at top right), but I hypothesise that if the original training context window was larger, this could’ve been addressed. Here’s how Claude, Cohere fared in the same test.

The authors also perform ablation studies on Attention to Mamba ratios, albeit on smaller models.

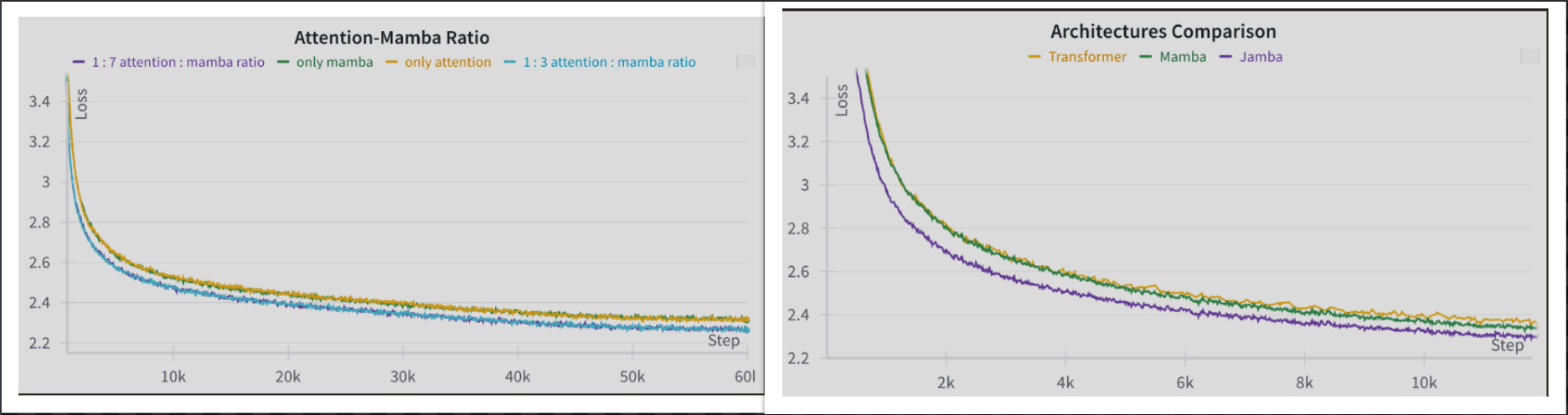
There’s very little difference in performance when the ratio is 1:3 and 1:7. So one would ideally prefer 1:7 cuz transformer is the hungry component. Less of them, the better. You now might ask, why use attention at all, Mamba seems to perform well enough. You’re not wrong if you thought so from the above results. But there’s a catch. The performance doesn’t generalise well to downstream tasks ig.
The reason they say is Mamba doesn’t adhere to correct output format. It tends to be on the right path but ends up using synonyms like bad for negative or very good for positive. Hybrid Attention Mamba model solves this. As an anecdotal evidence, they inspect an attention head’s attention. Clearly, it pays attention to the in context examples and hence has better chance of returning the same.


As expected, RMSNorm stabilises the training. While ROPE does add value, its not absolutely necessary. And MoE improves results by a fair bit.

And here’s Jamba compared to recently released DBRX. Jamba though is not as great as DBRX, its pretty respectable given that it has 52B params with 12B being inference active which is ~40% of DBRX
Grok 1.5
xAI aka Twitter released an update to Grok 1. This is a good opportunity to visit both of them. Grok was announced in November 2023 and recently had its weights released which claimed to have been of 2 months of training. There was an internal Grok 0 model which was of 33B parameters that acted as a stepping stone.
Architecturally, Grok 1 is a Transformer based model. It is made up of 314B parameters. Maybe, 314 as in π :) ? It has a context window of 8192 tokens which is small compared to the current standards but decent enough nonetheless. Vocab size is 131072 (same as Jamba lol). And it splits numbers into one token per digit. It being a MoE model, there are 8 experts per layer and 2 of them are active at inference.
The whole architecture consists of 64 layers. It has 48 query heads and 8 KV heads which means it is using Grouped Query Attention, which is a middle ground between Multi Head Attention (Q:K:V = 1:1:1) and Multi Query Attention (Q:K:V = q:1:1). Below image is an excerpt from GQA paper which aptly visualises these.

With the preliminary details out of the way, we can get into the rest. Grok-1.5 is a continuation of training of Grok-1 since Nov 2023. Unfortunately there isn’t much detail as to what has changed. But they shared only the results. Grok-1.5 definitely comfortably defeats Grok-1. It comes close to Mistral Large and Gemini Pro 1.5 while underperforming Claude 3 Opus and GPT4. It is well acknowledged that GPT4 and Claude 3 Opus are on league of their own.

Grok 1.5 does ace the Needle in a haystack test. The X Axis denoting the context length stretches till 128k. This is a huge improvement from Grok-1’s 8192.
Stable Audio 2.0
Stability AI, the company behind Stable Diffusion, which took the world by storm with its Image generation capabilities, and Stable Code, which had its CEO Emad Mostaque resign from his position has announced Stable Audio 2.0. Stable audio as the name says is an audio generation tool. Stable Audio 2.0 offers users to generate audio conditioned on text and audio with upto 3 minutes in length. The sample rate is 44.1kHz which is the same as Spotify’s sample rate :)
The model is available to try out on stableaudio.com. The results from my initial testing are good. The model can also be used to do style transfer on audio. Like stable diffusion, stable audio also uses Diffusion Transformer. It is trained on 80000 audio samples from audiosparx. And they partner with Audible Magic to perform copyright checks. Stable Radio is where the audio generated by Stable Audio is streamed on to youtube.
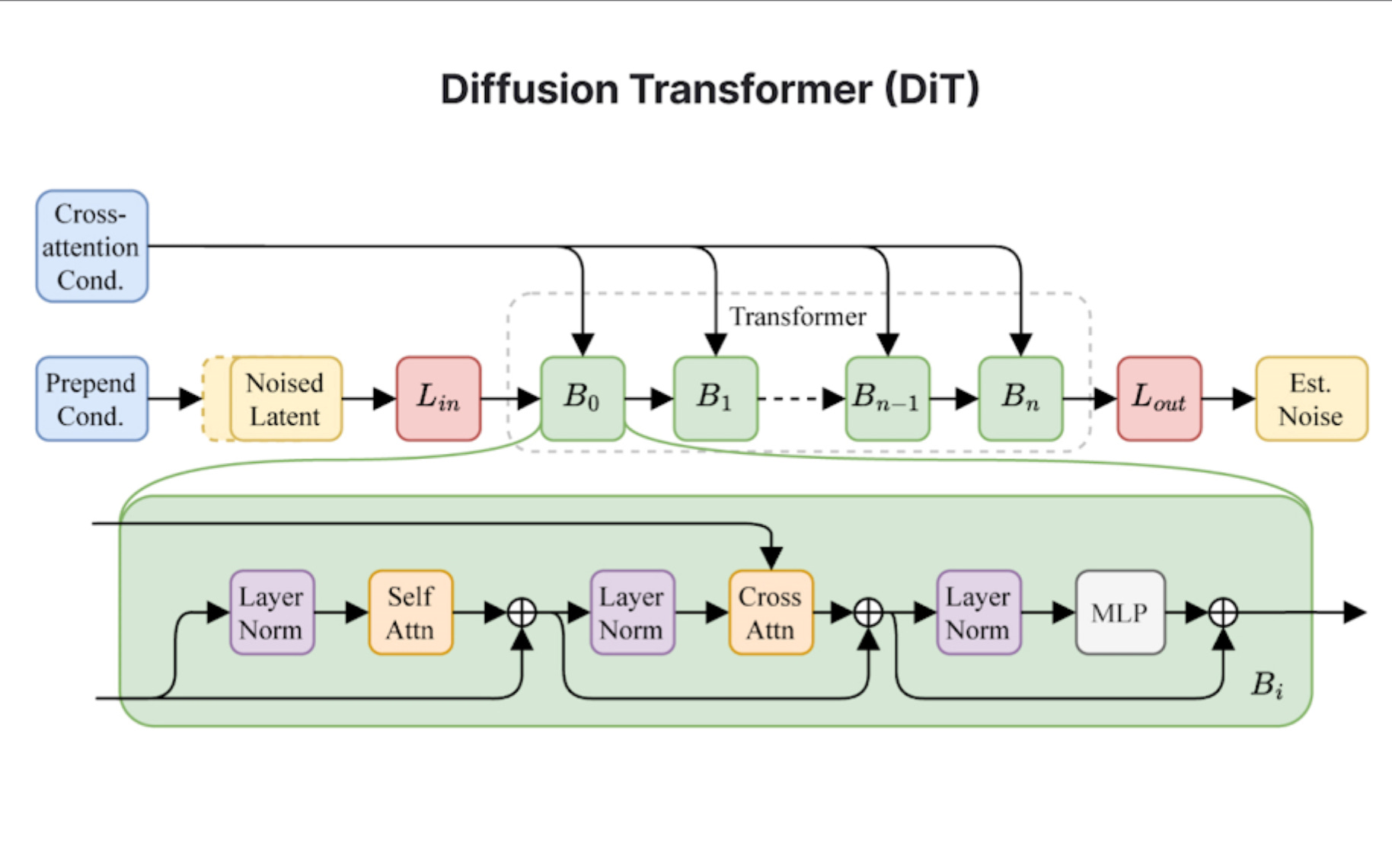
Cross Attention as seen above must be to attend to the text tokens and latent representation of the input audio. Remember that Stable Audio 2.0 also accepts audio as input.
You must be thinking audio is a continuous signal, how is it converted into tokens or some discrete representation. Generally, Audio models convert the audio into Spectrogram. Spectrogram is basically a histogram of frequencies over time. Now that the result looks like an image, we can use the same methods we use for Image genration.


STFTLoss is basically Short Term Fourier Transform Loss. The spectrogram we create is created using STFT. The loss is a combination of Frobenius Norm and L1 norm. Frobenius Norm is the sum of squares of eigen values. L1 norm is basically mean of absolute differences. Unfortunately, I’m not really sure what Snake block is.
Octopus v2: On device super agent
If you’ve ever tried Siri or Google Assistant for controlling your device, you’d know that they’re good for basic tasks but lack depth. They are cool party tricks with very limited usage. With all the progress in the world of AI, one would assume these assistants to have gotten better but they aren’t any more helpful than they were a few years ago. And if you remember people were running Llama 7B models on Pixel 5 devices almost an year ago :)
If you’ve seen open interpreter which looks like a cool way to control your computer and wanted something similar, this paper is a step in that direction. For the task at hand, we don’t need world knowledge and understanding of theory of relativity. So, you probably won’t need a big LLM that is running on someone’s servers. Add to that its a privacy nightmare to let data leave your device and reach that powerful models.
Function Calling/Tool usage has seen rapid development from the days of ToolFormer. If you put every bit together, you can probably have a small model, fine tuned for tool usage aka smartphone controlling that can run locally at great speeds.
To use a tool (Functions), the model needs to know which tool to pick among the possible options and what parameters to use. Language models split words into one or more tokens. This can lead to hallucinating function names that don’t exist. So the authors create new tokens one per each available function. For this, you have to modify both the embedding matrix and the language modelling head (lm_head).
This is how a sample data point looks like. First is the system prompt. Then the user query followed by model response. <nexa_i> is the special token associated to the function being used. There’s a <nexa_end> token that suggests the end of function. Special tokens are important when it comes to LLMs. Function description is additionally added to provide the model with more context.

Now that we’ve formulated the task this way, we don’t need RAG anymore. WE need to fine tune the model and we’re good to go, thus reducing the prompt lengths and hence latency. They also compare full fine tune to LoRA fine tune (r=16 alpha=32 on all modules) for 3 epochs
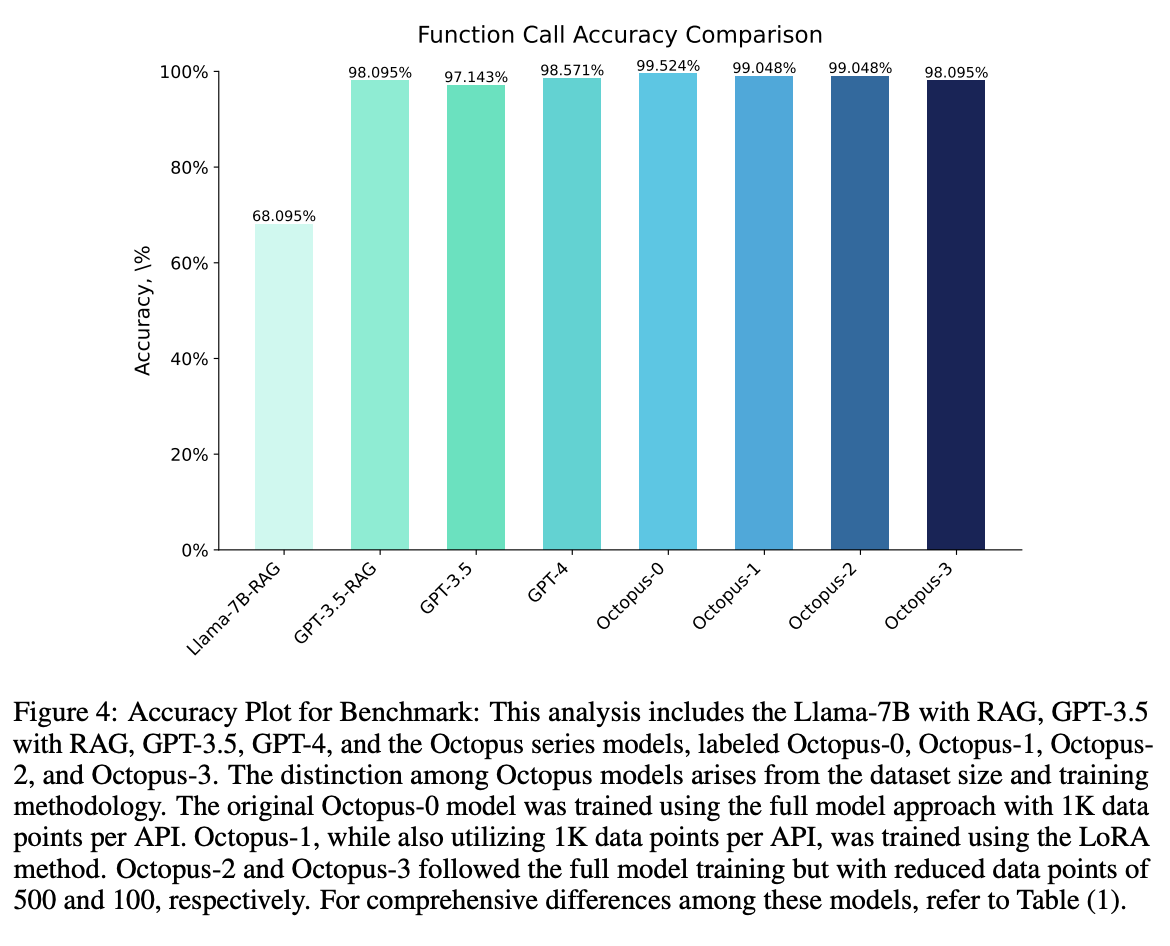
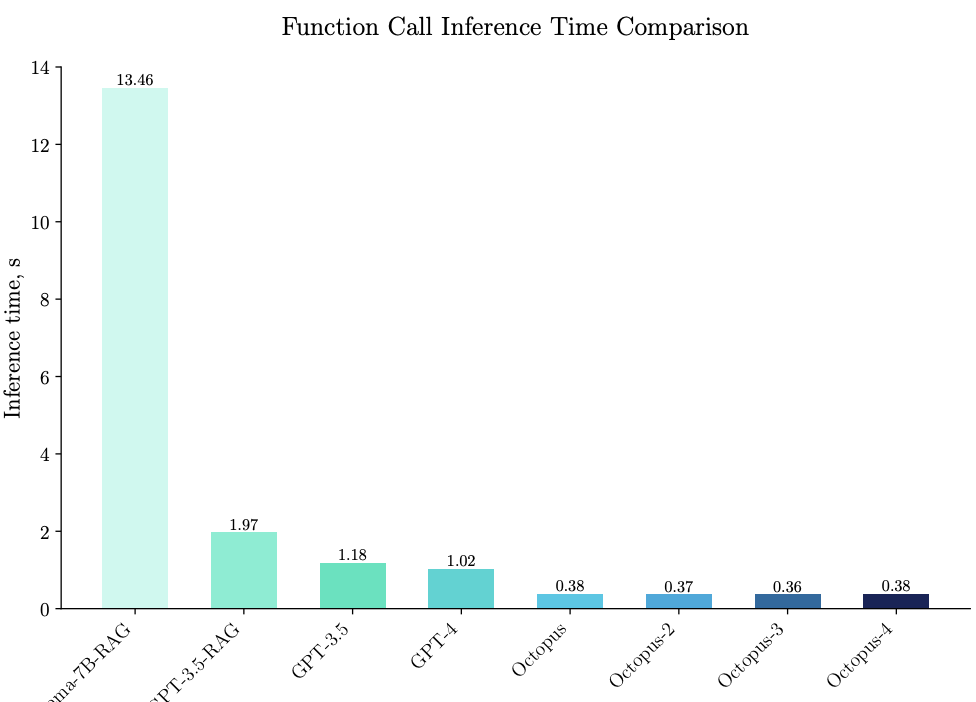
Though GPT 3.5 performs good, llama 7b is mediocre at best. And the same patterns hold for latencies as well. The model being run is Gemma 2B :)
Coming to the implementation details, to address the challenge of imbalanced dataset because we added new tokens, they modify the Cross Entropy Loss function to a weighted one with new tokens having more weight. But experiments show that there isn’t much difference whether the new tokens are given higher weightage for loss or not.
Unfortunately, there isn’t much comparison to how it fares versus other mobile assistants like Google Assistant which now runs on Gemini Nano and a lot of processing happening offline too. Siri is very behind in the game anyway. But if rumours are to be believed, Apple is set to announce major AI stuff for iPhones this WWDC and iOS18. They were even rumoured to have been in talks with Google for Gemini lol. Fingers crossed :)