
AI Unplugged 5: DataBricks DBRX, Apple MM1, Yi 9B, DenseFormer, Open SORA, LlamaFactory paper, Model Merges.

Table of Contents
Databricks DBRX
Apple MM1
DenseFormer
Open SORA 1.0
LlaMaFactory finetuning ananlysis
Yi 9B
Evolutionary Model Merges
DataBricks Mosaic DBRX
If you remember, databricks bought out Mosaic last year. Mosaic was the team behind the infamous MPT series of models and instruct v3 datasets. Now they’re back with a big, and surprise surprise, Mixture of Experts(MoE) model this time. And DBRX sounds like a (possible) ticker symbol for Data Bricks…
Talking about the architecture, this is as usual, a Transformer based MoE model. In total, it has 132B params out of which 36B are active for any input. Remember that when an expert is chosen for inference of a text/token, all the other experts in that layer are unused. So what we can infer from this is, approximately 1/4th (36/132=0.27) of the experts are chosen. And in fact, if we look at the details, there are 16 experts out of which 4 are chosen, while for Mixtral and Grok, it is 2 chosen from 8 experts.
Digging into the model config, we notice that the hidden dimension is 6144. The FFNN hidden dimension is 10752. It uses ROPE for positional embeddings. Grouped Query Attention is employed. The attention matrices are fused (for efficiency reasons) They also clip the attention values between -8 and 8. TikToken’s GPT4 tokeniser is used resulting in a vocab size is 100352. Tiktoken splits numbers into 1,2,3 digit parts (so basically there are 1000 tokens one for each number between 0 to 999) which arguably helps with math.

On data front, DBRX is trained on a whopping 12T tokens with a context length of 32k. For reference, llama2 family was trained on 2T tokens. They also claim that the data they used is 2x* better than what they had for training MPT family.
Compared to open models, this model outperforms the competition by a fair distance, including Grok which is a 314B parameter model aka 2.4x the size.

There’s an interesting paragraph in the blog. They say that a member of the DBRX family, 7.7B model with 2.2B active params, reaches similar eval score on Databricks Gauntlet with 3.7x less flops. This is very very likely due to improvement in data. Quality data is the key to everything. And, it took 3 months of training on 3072(!) H100s. Databricks approximately spent 10M$ for the whole training which is fractional compared to what OpenAI would’ve
If you want to run these models locally thought, tough luck. Big MoE models are basically meant for enterprises with high memory and compute bound. For an average RTX 3090 user with 24GB VRAM, MoEs are generally way beyond the budget. There’s an active PR to run DBRX 4bit quantised on M2 ultra, but the demo uses ~70GB VRAM.
You can try out the instruct variant in this huggingface space. And here’s the possible system prompt.

As to how it fares, it starts with wrong answer and ends up with the right conclusion for pound of bricks vs kilo of feathers question. Here’s how Claude3 and Mistral large fared for the same. It also fails to answer Le Cunn’s 7 gear problem by default.


Apple MM1: Multimodal modal analysis
Apple, yes the Apple, released a paper detailing about Multimodal aka Vision Language models. The following is an excerpt from the same. Pretty interesting that they out of all, have come up with a detailed study :) Pretty amazing. Lets dig in.

The components shown in the below figure are configurable. And the current study is done by modifying one part of the stack at a time and observing the effects.
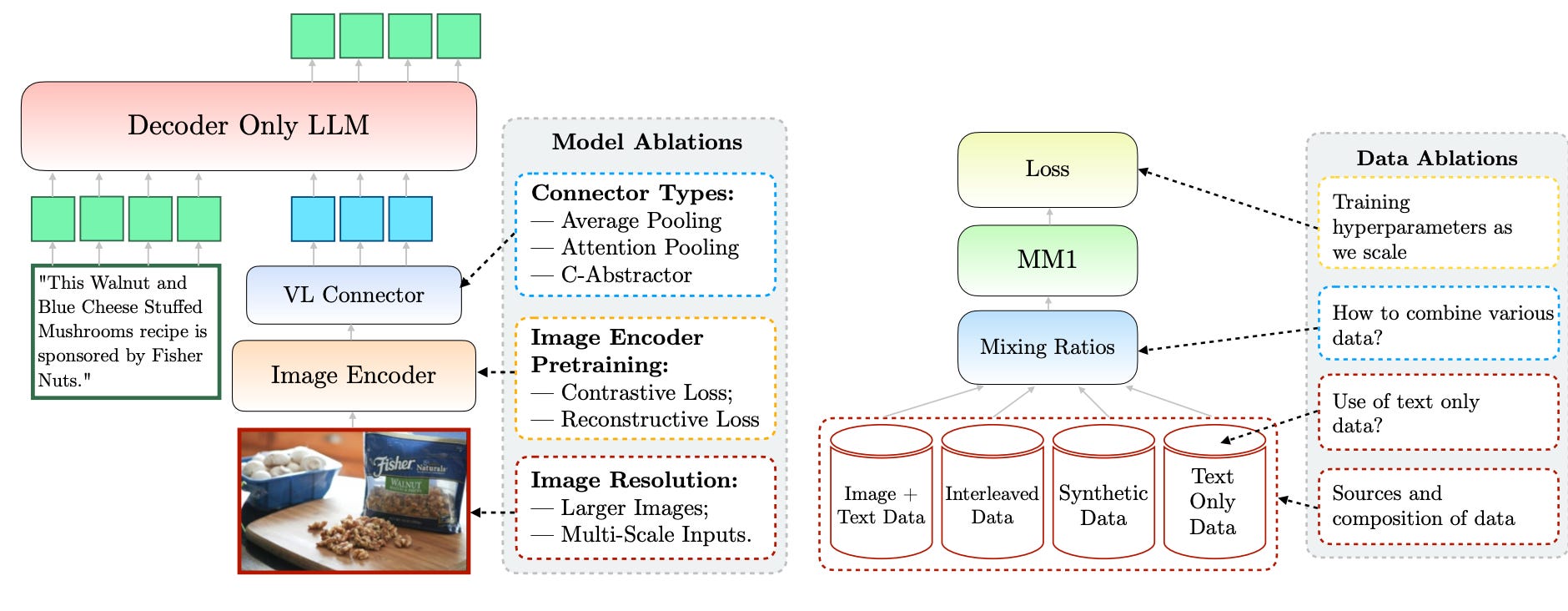
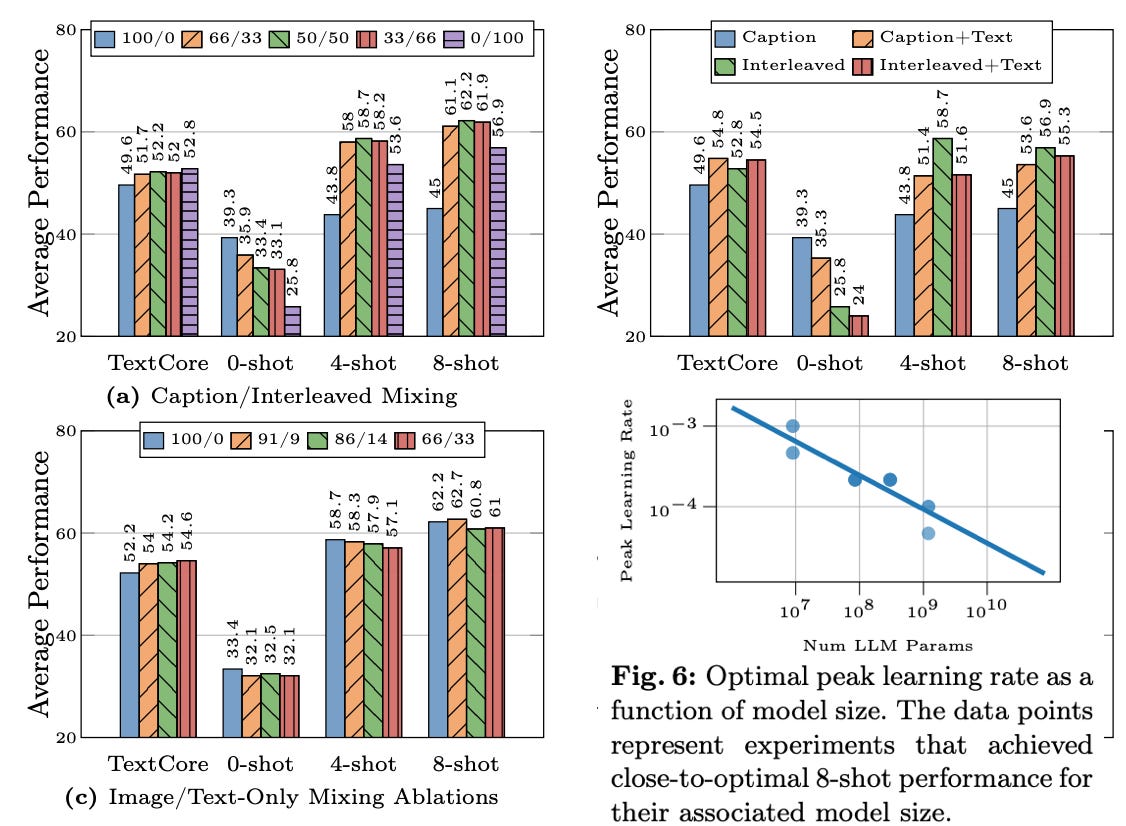
As you see in the below graphs, Image resolution has the highest impact on performance. Going from 224x224 to 336 ~2x tokens gives an approximately 3% increase in performance, while 2x. And for pooling the features, there’s no clear favourite. Surprisingly, Attention pooling performs worse compared to Average or Convolution.

As for the data, Image interleaved text data (image between text) found usually on websites or blogs seem to be better than captioned images (from something like instagram) as the former would be more descriptive. Also careful mixture of Captioned, Interleaved and Text only data can lead to optimal performance. Around 5:5:1. Synthetic data too improves performance :)
Their study on learning rate reveals that optimal learning rate is inversely proportional to the LLM parameter size and is given by the equation
DenseFormer
The proposition is a mod to the existing Transformer architecture. A way to improve it. Simply put, instead of using output of only the current layer as inputs to the next layer, also give some consideration to the outputs of previous layers. Remember skip connections from Conv Net or UNet days? Or “memory” in RNN? There’s a clear analogy there.
So how does DenseFormer work you ask? The outputs of previous transformer blocks, are passed to a DWA (Dense Weight Average) layer before sending as input to the next layer. So at layer k, we take weighted average of outputs of the last k-1 layers. And the weights are learnt. Hence, a total of d(d+3)/2 parameters in total. Which is minuscule compared to the total parameters. And yeah there’s memory overhead of storing all those outputs. Which is h items per block and d blocks aka hd weights.
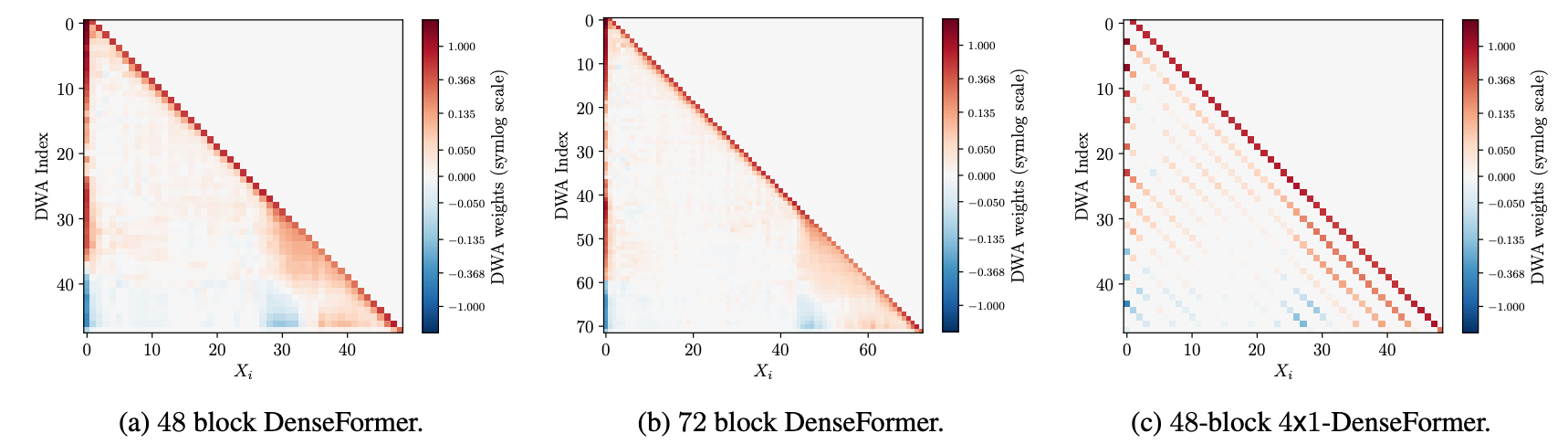
And there’s another variant where you don’t average on all the layers’ outputs but pick some, like picking a few layers periodically. And maybe ignoring some from even that. This would result in selection map that looks like below.

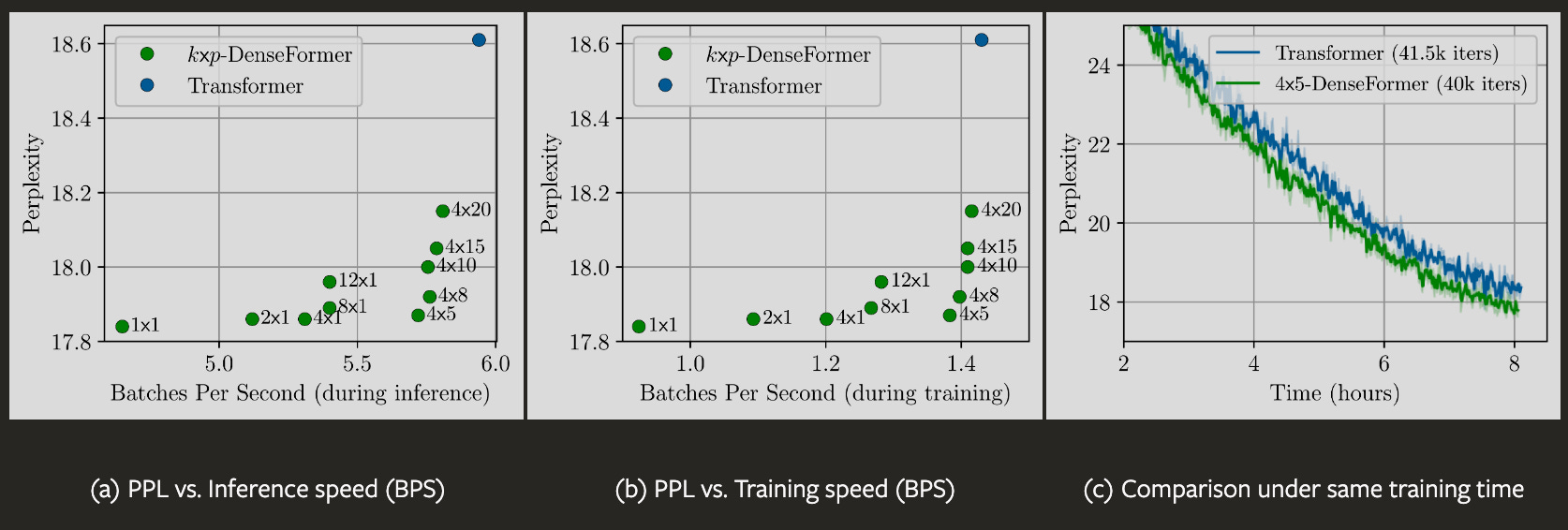
This is how it fares against the usual Transformer in performance and metrics. As you can see, DenseFormer has much less perplexity than Transformer at given inference/training speed constraint. A little performance trade off is worth it for this delta in perplexity though. Note that they trained very small models for this.
So upon checking the weights learnt, we see clear emergent patterns. There’s high weight on diagonal meaning high weight to immediate previous layer’s output akin to the normal transformer. The high weight in the initial column means those layers are attending, for the lack of a better word, to weight embeddings. There’s higher weight last layers give to their previous layers and these layers don’t attend to embeddings :)
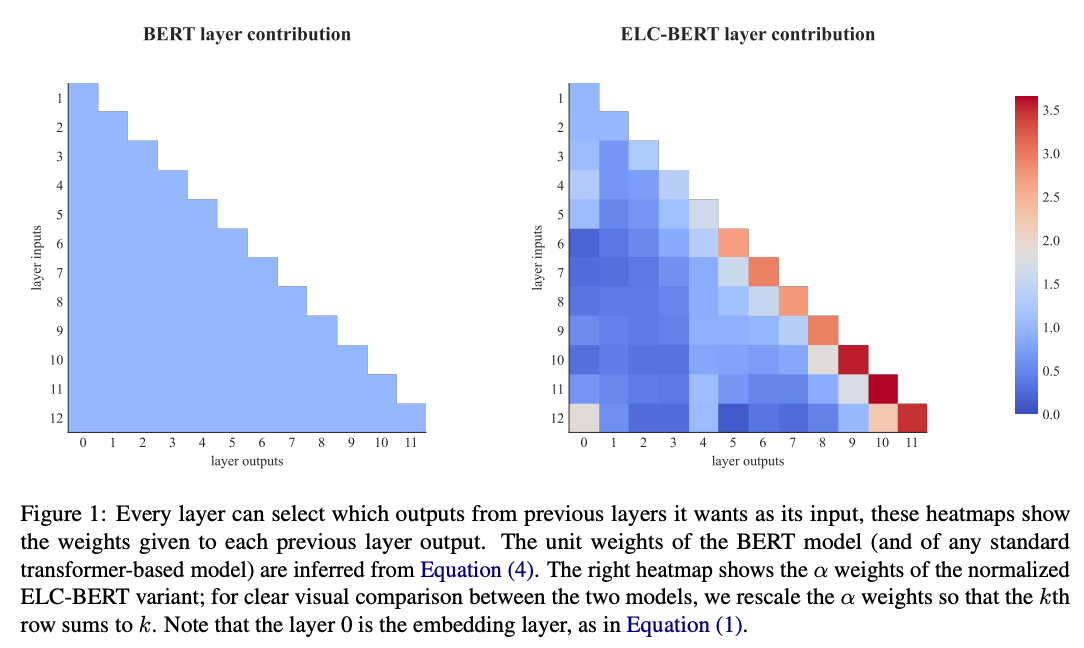
Now that we’ve looked at it from all angles, there’s something I’d like to draw your attention to, thanks to Daniel Han from unsloth. Below image is an excerpt from Every Layer Counts BERT. They also explore something very similar. Maybe a case of rediscovery :). Anyway cool stuff…
OpenSORA 1.0
Remember OpenAI SORA that we previously talked about? This is an effort to replicate that with being fully open source from architecture to data to everything. Check it out on Github.
The architecture is the usual Diffusion Transformer. The work is based on PixArt-α, an efficient Text to Image model. Temporal attention is then added to the same to extend it to generate videos. Here’s how the architecture looks.

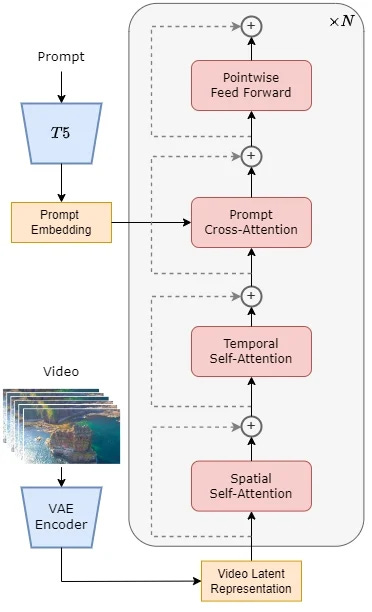
The above image is how the STDiT part of the architecture looks like. The Prompt cross attention you notice is for video embeddings to attend to the prompt. They also split up video part into 1D temporal and 2D spatial attentions. This is efficient compared to doing attention over space-time-text triplets.
In training stage, video is compressed by VAE (Variational Auto Encoder) encoder and fed into the STDiT. For inference, we sample random noise from latent space of encoder and is sent to STDiT along with text prompt.

Training consists of three stages:
Large Scale Image Pre-training: Videos are multifold expensive compared to Images. So we start with Image pre training and then expand to videos. After all, Video is just images moving fast enough. The second stage pre trains on videos by adding temporal sequence attention. The whole is then fine tuned on high quality videos in the third stage.
The total cost of training is ~11k$. For data processing, videos are clipped based on shot continuity. Then they are tagged (add description tags) using LLaVa 1.6 Yi 34B.
Also, do take a look at the demos here.
LlamaFactory: Unified Efficient Finetuning
The people behind the popular fine tuning library, LlamaFactory which made fine tuning as easy as filling a few details in a file, has released a paper comparing Fine tuning techniques. Now they also have a friendly UI to ease the process.
In the paper, we’re comparing various efficient fine tuning techniques like GaLORE, LoRA and DoRA. Before getting started, let’s take a brief look at each of the methods.
Initialisation is basically loading the model weights.
Patches are things like Flash Attention, Unsloth to speed up fine tuning.
Adapters refers to LoRA (w/ unsloth) and DoRA for memory efficient tuning.
Quantisation is where we reduce precision of weights from FP32 to FP/BF16,Int4..

Freeze tuning adds few layers on top of existing ones and updates only them.
LoRA adds low rank adapters to the Attention/MLP layers and trains them.
GaLore projects gradients to low dim space hence reducing memory usage.
DORA decomposes magnitude and direction of LoRA adapters and trains them.
With introductions and explanations out of the way, let’s get into the results…. In terms of Perplexity (lower is better) and throughput, LoRA stands the clear winner. QLoRA is obviously memory efficient as we load weights in 4bit precision.

Now lets look at downstream performance, measured in terms of ROUGE scores. LoRA still comes out on top in most scenarios. Interesting thing here is, QLoRA sometimes outperforms LoRA especially Gemma or XSum. Probably low precision avoids overfitting? Something to ponder upon…

Yi 9B Dive deep
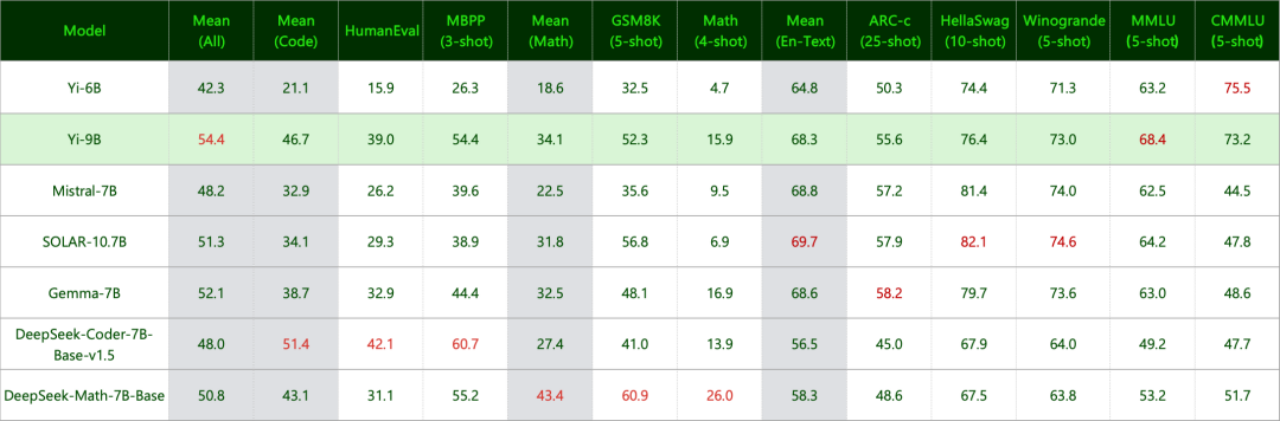
Yi 34B has been a widely acclaimed model by the community for its prowess. This blogpost covers how they modded their other model, the Yi 6B to improve it on Math and Coding abilities. Curious to know what was done? Lets dive right in…
So, they take the 6B model. Find a few layers, replicate them and end up with 9B model. They also mention why they did what they did. I highly encourage you to read the blog. I’ll summarise in a few sentences.
Increasing the model width doesn’t seem to be improve the performance.
Increasing data alone isn’t enough to provide any benefits.
They train the model in two stages. One where data is of same proportion as initial Yi 6B training. Later, they increase the proportion of Math and Code.
No learning rate scheduling. They increase the batch size over epochs.
How do they expand? They find the cosine similarity between input and output of layers. They find that for Yi34B and Llama70B, a lot of layers have similarity of close to 1.0 while that isn’t the case for Yi 6B. So they replicate 16 layers (layer 12-28) with similarity close to 1.0.
There’s a similar work called Solar which replicates the middle 16 layers (8-24) of Mistral. Yi’s method’s results are compared to Solar too and it emerges victorious.

Evolutionary Model Merges
This blog post from sakana.ai explores model merges. Model merges, also called as Franken Merges, have been an area actively explored by the community, though explored very scarcely by academia/companies. Sakana has decided to give it a try, and they share their findings with us. Yay!

So why have they decided to explore merges? They had some good performing Japanese models and some do well on math. But they couldn’t find one that does both.
So to explain model merges, people aka the community to different things. One of the ways, Parameter Space is, to do a weighted average of different layers of models. This works when the architectures are similar. Data Flow Space, the other way is to pass the input through layer/model and then from a layer/block of another model. There’s no explanation as to why these work. Let’s say it is all attributed to Divine Benevolence ;-)
This sounds a lot similar to Gene Mixing right? Thats probably what Sakana team thought too. Hence, they wanted to introduce the concept of evolution to model merges. Simply put, try different kinds of merges, find out what works and pass those onto next generation (akin to dominant/winnings genes).

As you see in the results, this works magically well on Multi Lingual GSM Japanese (MGSM Ja). Note that there’s no info on the compute required to perform the so called evolution. All we know is that it took them 150-200 generations.

One interesting thing that happens is, this merge outperforms models of much higher parameter count. Probably this is something where more research happens in the coming months. If it is as good as the promise, this will be tremendous. The best part is, this is agnostic to input/output modality…