


AI Unplugged 4: Stealing LLMs, GaLore, Training LLMs at Home, SIMA, Unsloth and Cohere CmdR

Table of Contents:
Stealing Part of Production LLMs
GaLore: Memory efficient LLM training
Training LLMs at Home
DeepMind SIMA
Unsloth Fixes Gemma
Cohere CmdR
Stealing Part of Production LLMs
This paper claims that we can understand a lot about parts of the LLM even when it is black box aka behind an API only access. They start with the claim that they found out that the OpenAI’s ada and babbage have hidden dimension of 1024 and 2048 respectively. They extracted embedding layer of several of OpenAI’s models upto an Mean Squared Error of 10^-4.
This relies on the fact that hidden dimension (h) is generally much smaller than the vocabulary size (l). This means the final lm_head projects from a low dimension (hidden dim) space to a higher dimension (vocab size) space. Hence it would have low rank. For example, below is the lm_head for Llama2-13b. All the attacker needs, is the full log probs (aka probabilities over vocabulary) that is generally available via API.
(lm_head): Linear(in_features=5120, out_features=32000, bias=False)So if you know the output vectors of lm_head per query (without softmax for now), and do more than h queries (we don’t know h in adavance, so we’d do thousands of queries), given that the vectors were initially in a h dimension space, performing SVD on the output vectors would give you the dimensionality aka hidden dimension h (in practice, you might get a smaller value but repeating with different combinations can help here).
One key thing to note is, given that the numbers are represented as FP16 or FP32, there’ll be a lot of non zero yet non significant eigen values. So they calculate numerical rank aka for ordered singular values, λ1 ≥ λ2 ≥ · · · ≥ λn, the largest λi/λi+1 would be considered as switch from actual values to numerical imprecisions.
For Pythia 1.4B, above mentioned fraction is plotted on log scale. And they repeat the experiment for other open weight models to confirm the workings.

The most interesting part of the whole is that, once you form a matrix with the log probs, Q, the singular value decomposition Q = U·Σ·V, U is basically the lm_head weight matrix (upto some rotation). The difference is mentioned in the above table. Note that for random matrix, the W RMS would be of order 2 · 10^−2.
There are some fine details about how they manage to attack models that only return softmax outputs and that too with logits of only top-k tokens. They use logit bias (aka adding a value to prob of that token) for this. You can look at the paper for details. The math is simple enough to follow and appreciate :)

GaLore: Memory efficient LLM training
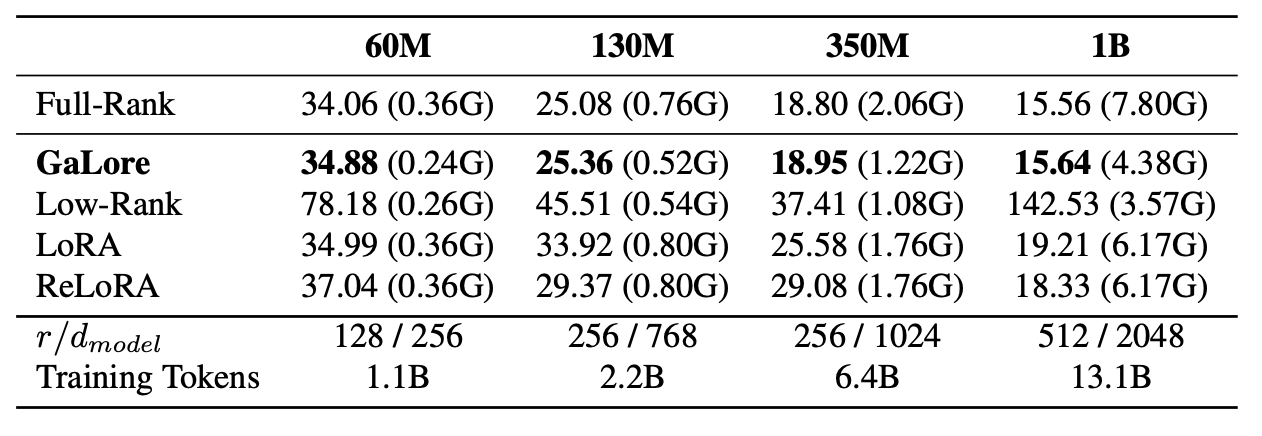
GaLore presents an interesting approach for training and fine tuning LLMs with considerably lower memory. They propose that the gradients at every step are intrinsically low rank. Below is a representation of how much memory each part/ type of parameter consumes. Note that the graph is for Adam optimiser. Adam keeps track of momentum and variance of the gradient along with gradient itself. So its pretty intensive on memory. In fact, generally ~3x the weight size if in same data type.

The crux of the paper is, given that gradient matrix is low rank, we can project the gradients into a lower dimension (r) space. We track momentum and variance in this low dimension space. Once we update these with Adam, we project it back into original dimension (m x n) to update the weights of the network.
This work heavily relies on a previous work called LoMO: Low memory optimisation of LLMs (paper). The trick is, as soon as you find the gradient of last layer, you update it and calculate the gradients of last but one layer so that at one point, you only need to store the gradients of only one layer thus reducing memory footprint tremendously. But this technique fails when you use gradient accumulation (basically you use small mini batch, wait for a few such mini batches’ gradients and then do back prop thus emulating larger batch size). In this case, you can’t just apply gradient as you get it.
But now with GaLore, you can store and track gradients (and momentum) with very low memory (m*r+r*n vs m*n). Combine both the techniques and you have a katana in your armoury. The low dimension projection is done via our good old Singular Value Decomposition(SVD).
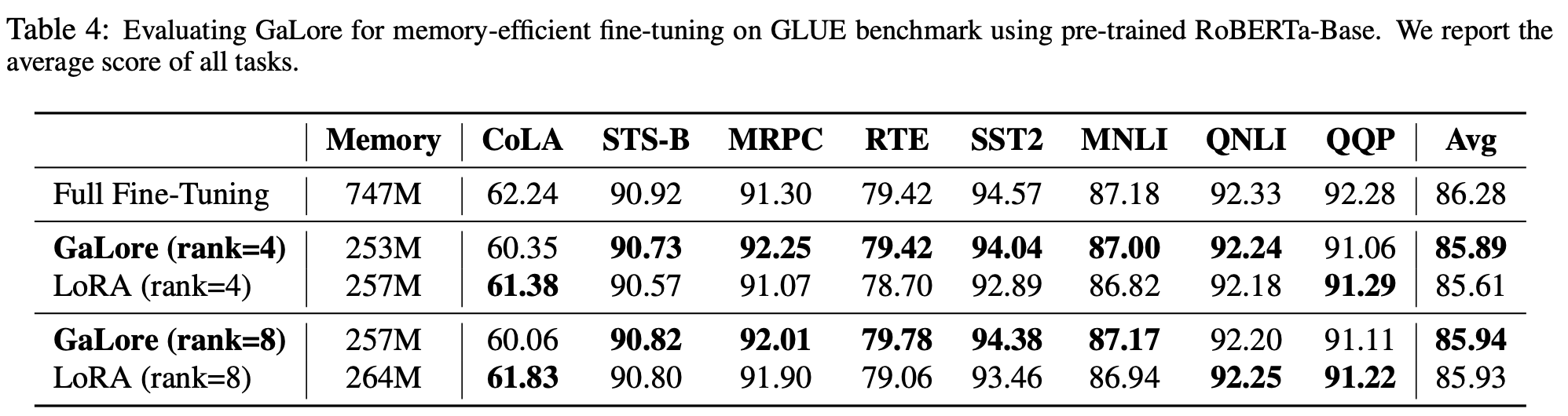
Overall, this technique consumes memory similar to LoRA but performs similar to full fine tuning in terms of accuracy, losses and perplexity.

Training LLMs at Home
This blog from answer.ai shares how to train LLMs at home aka on consumer grade GPUs. Generally, NVIDIA’s RTX 3090 and 4090 aren’t much far from A100s in terms of performance but the key difference lies in Memory capacity and bandwidth.
The secret sauce you ask? Its basically QLoRA (loading weights in 4bit) and FSDP.
FSDP is Fully Shared Data Parallel. It basically splits the model across multiple GPUs and computes part of the network in each GPU, passing information as in when required and combine all the results later. For example, say first 10 layers of LlaMa 2 7b on one GPU, 10-20 on another etc and you pass the input through GPUs in order and pass the hidden states from one GPU to another, collate everything, calculate gradients and do back prop. There are techniques to speed this up and make utilisation optimal like Zero.
And coming to the details of quantisation, they use HQQ which does quantisation closer to the speed of BnB 4 bit with accuracy on par with AWQ aka the best of both worlds.
DeepMind SIMA: Generalist AI
Scalable Instructable Multiworld Agent (SIMA) is an AI that can follow Natural Language instructions (like climb the wall, open the chest) in interactable game environments. Deepmind collaborated with Game Developers to train SIMA on a wide variety of video games.
The other week, we explored GENIE, which generates playable environments. For Reinforcement Learning, you need agents (that perform actions) and environments(where actions are performed). For each action or sequence of actions, there should be numerical reward. The agent keeps exploring environment to harness higher reward as the training goes on. So this work is complimentary to GENIE along the agent dimension.
Here’s the architecture of SIMA. As expected, there’s Text and Image encoders. There’s also Video Encoder. These are pre trained models that are fine tuned for this task (for eg, video encoder was fine tuned on game play videos). Taking all this in, the model in the end produces Actions (similar to Keyboard/Mouse inputs). This as usual is a Reinforcement Learning based model.

The evaluation is done as combination of verifying against Ground truths (labeled data), Human Eval and OCR (some games provide the action taken as text on screen). Here’s how SIMA performed on those evals across games.

There’s also evaluation on per action basis. Movement seems to be the easier task to master, probably because it is similar across games.

Unsloth fixes Gemma
Gemma infamously was notoriously hard to fine tune properly. 7B sometimes ended up underperforming the 2B variant raising concerns. But Daniel Han from unsloth.ai came to the rescue. He dived in and fixed countless bugs and now its performing up to the mark. The blog is super informative and worth a read. Here’s a short list of what all had to be fixed.

Cohere Cmd-R
Cohere launches CmdR which is a model focused primarily on Retrieval Augmented Generation aka RAG and Tool usage. They also release the model weights on HugginFace. Here is how it performs on RAG and tool usage. It is a 35B parameter model and outperforms the likes of Mixtral (8x7B), LlaMa 2 70B and GPT 3.5. And it has amazing success doing the needle in a haystack test.

