
AI Unplugged 20: SCoRE Self Correction via RL, OpenAI o1 models, Qwen 2.5 coder, Spectrum Fine Tuning.
Insights over information



Table of Contents:
Training Language Models to Self-Correct via Reinforcement Learning
Qwen 2.5 Coder : Technical Report
Spectrum: Targeted Training on Signal to Noise Ratio
Learning to Reason with LLMs: OpenAI o1 models
Training Language Models to Self-Correct via Reinforcement Learning
TLDR:
Multi Step Reinforcement Learning to teach model to self correct its mistakes. First step trains the 2nd attempt while trying to not modify the first attempt. Second step trains both the attempts together towards correctness. Without these, model learns to not change its outputs. SFT is not a viable choice for this cuz it has equal-ish chances of correcting the wrong output vs messing up the right ones.LLMs make mistakes. So do humans. But what sets humans apart from LLMs is that humans can realise their mistakes and self correct themselves. This has not yet been done for LLMs as they are mostly trained to output the right thing. And sometimes the models start with an approach, even on realising later that the approach was wrong, they cannot go back and correct. They continue treading the wrong path happily. Sometimes when they see the information of previous attempt and user’s feedback on it, they tend to correct themselves. Now the question arises, can you teach the model to understand its own mistakes and correct them?
There are different ways. One such way is to use a verifier (model or algorithm) which verifies the output (solution) of the model, gives it feedback to reiterate on the same question. There are works which use a big and more capable model for feedback. Some setups use compiler execution as feedback. But the problem with these is that they rely on an external entity for feedback and the inference is generally multi hop.
Well most of the tasks are modelled as next token prediction. Even from that task, LLMs show emergent capabilities like instruction following, question answering, reasoning (well if you believe so). So in theory one can feed in data of question, followed by say a wrong answer which is then followed by the correct answer probably even highlighting the mistake in the previous attempt to help model understand. If you train on such a dataset, there is a chance that model might start to learn to make mistakes more than correct from them. It can learn to generate wrong answers in first attempt only to possibly correct them later, thus defeating the purpose. Another problem here is that, the mistakes you train on might not be the model’s mistakes but some random ones. Even if you do use the current model’s mistakes, they will be outdated for next iteration. So there’s a distribution mismatch.

Whenever we want to teach the models to learn by exploration and not stick to the hard training labels, whenever there is a preference data of what is good and what is bad (pseudo-reward), or to use the agent’s actions (model output) for feedback, the obvious choice is to perform Reinforcement Learning. And particularly, in this case, Online Reinforcement Learning where the output is generated based on the current model weights. It is named SCoRE aka Self COrrection via REinforcement Learning.

So how does one tackle the above said problems? For the case of model generating same set of solutions , we train the model in two steps. In the first step, the model is incentivised to generate correct solutions for second attempt while making sure that the first attempt is as close to original SFT as possible (KL div ensures that). The r(y2, y*) maximises the reward for y2 aka 2nd attempt output. This is assumed to teach the model correction capabilities.

Then in the second step the model is trained to maximise the reward of both the attempts. The loss is very similar to the previous step but it goes over both first and second attempts. There’s also additional bonus given to those generations where the reward increases in the second attempt to bias towards correction. This is called Reward Shaping.
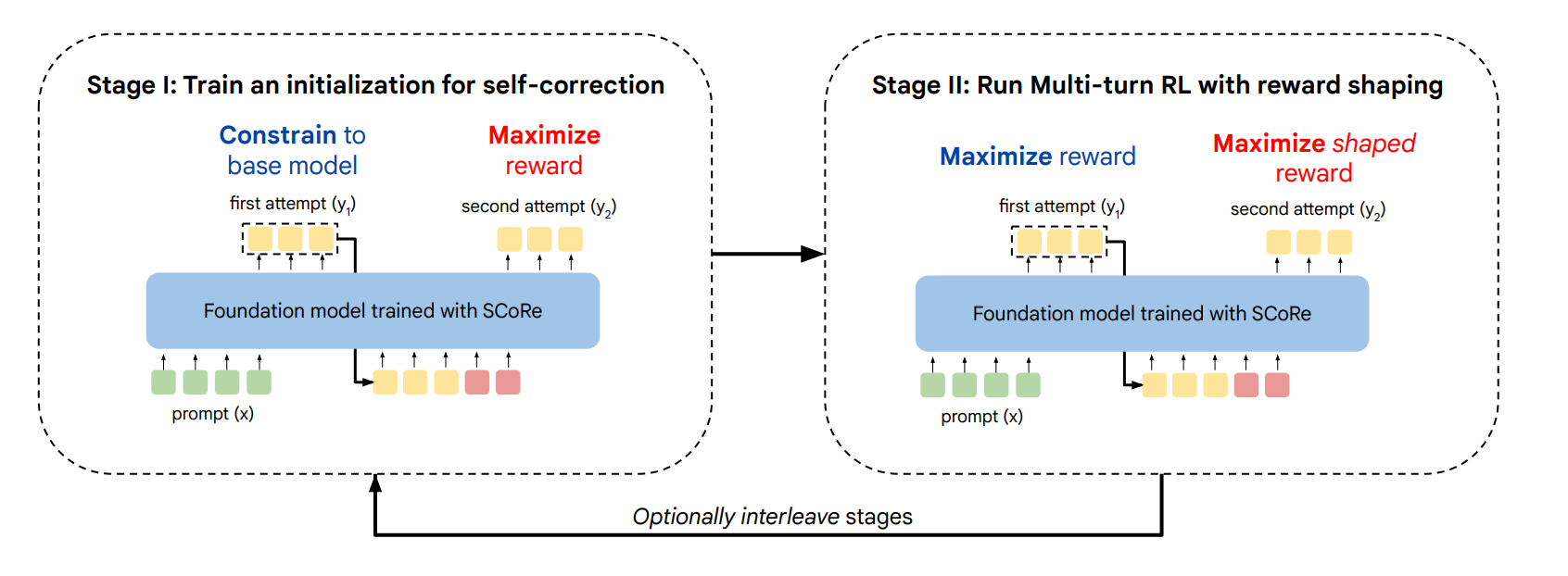
And the steps are interleaved so that the policy is never too outdated. Now how does this method perform? Well for something like correction, along with final accuracies we also need to measure how many times corrections help vs hurt. Let us compare the same with previously known techniques like STaR and SFT data. Score definitely outperforms those. t1 and t2 are attempts 1 and 2. Δ(t1,t2) the difference in correctness of two. Δ i→c denotes those who went from incorrect (first attempt) to correct solution (second attempt) and Δ c→i is the reverse. As you see, approaches like STaR and Pairwise SFT have equal amount of solutions getting correct vs failing.


Fortunately there are ablation studies done to understand the impact of each of the steps/decisions in the final improvements.

Techniques like these, help elevate the model capabilities. If you’ve followed the space in the recent past, and have heard of o1-preview which does long thinking before output, it was Reinforcement Learning behind that. Reinforcement Learning is the backbone behind AlphaGo, AlphaZero which dominate Go and Chess respectively achieving super human performance. This, though isn’t truly completely RL, is a way in the right direction. Giving the model a chance to rectify its own mistakes is always welcome.
Qwen2.5-Coder Technical Report
TLDR:
Qwen 2.5 (coder) family of models are highly appreciated by community. This comes in 1.5B and 7B variants trained on 5.5T tokens including PRs, notebooks, kaggle datasets. These models outperform DeepSeek-V2 models of their size range.The world of large language models (LLMs) is constantly evolving, and now we’re seeing more models designed specifically for coding tasks. These code-focused LLMs—like StarCoder, CodeLlama, DeepSeek-Coder, CodeQwen1.5, and CodeStral—build on general-purpose LLMs but are optimized for handling code-related challenges. Now, taking it up a notch, the Qwen2.5-Coder series brings new models designed to excel in coding tasks, available in two sizes: 1.5 billion and 7 billion parameters.
Both models pack 28 layers and come with a head size of 128, but the differences are in their hidden sizes and head configurations. The 1.5B version has a hidden size of 1,536, with 12 query heads and 2 key-value heads, while the 7B model bumps that up to 3,584 hidden size, 28 query heads, and 4 key-value heads. Oh, and the intermediate sizes scale too—8,960 for the 1.5B model and 18,944 for the 7B. Another interesting tweak: the smaller model uses embedding tying, where same weights are used for embedding and unembedding (lm_head), but the 7B skips that. Both models share a hefty vocabulary size of 151,646 tokens, and they’ve been trained on a staggering 5.5 trillion tokens.

What’s cool about Qwen2.5-Coder is the diversity of data it’s trained on. The dataset behind it—aptly named Qwen2.5-Coder-Data is a well-curated mix, with 5 main components:
Source Code: The backbone is open-source code from GitHub (up to February 2024), spanning a whopping 92 languages. It’s not just code either—they threw in Pull Requests, Commits, Jupyter Notebooks, and even Kaggle datasets for good measure.
Text-Code Grounding Data: Sourced from Common Crawl, this includes documentation, tutorials, blogs basically anything that bridges text and code. And to make sure only the best stuff gets through, they used a hierarchical filtering method to weed out the noise.
Synthetic Data: Here’s where things get clever. Using the earlier CodeQwen1.5 model, they generated synthetic data—but with a twist. Only executable code gets through, thanks to an executor that checks for correctness. Less hallucinated junk, more legit training data.
Math Data: To up its math game, they pulled in data from the Qwen2.5-Math corpus, and surprisingly, it didn’t mess with its coding skills. Win-win.
Text Data: Finally, they added high-quality natural language data from the Qwen2.5 corpus—but stripped out any code-related bits to avoid duplication.
After all that, the final dataset for Qwen2.5-Coder was 70% code, 20% text, and 10% math, totalling 5.2 trillion tokens.
When it comes to instructions, things get even more interesting. They built a massive instruction dataset from code snippets scraped off the web (think GitHub) using an LLM to generate prompts and responses. To make sure the data was solid, they graded it on a bunch of factors—consistency, relevance, code quality, clarity, and even educational value.

Evaluation-wise, the Qwen2.5-Coder series went through the ringer. It was tested across six areas: code generation, completion, reasoning, math abilities, natural language understanding, and long-context handling. They compared it against the best out there—like StarCoder2 and DeepSeek-Coder—and it held its own in a big way. For benchmarks like HumanEval and MBPP, it even got tested on enhanced versions (HumanEval+ and MBPP+) to really push its limits. In terms of code completion, its Fill-In-the-Middle training approach made it a star across Python, Java, and JavaScript—beating out larger models.

What really stands out about the 7B model is how well it performs on reasoning and long-context tasks. It can handle sequences up to a jaw-dropping 128K tokens, as shown in the Needle in the Code task, and outperforms larger models like CodeStral-22B and DS-Coder-33B in key areas like code generation, reasoning, and text-to-SQL tasks. Even with fewer parameters, it managed to outperform its bigger counterparts in benchmarks like HumanEval, LiveCodeBench, and McEval.
Spectrum: Targeted Training on Signal to Noise Ratio
TLDR:
Spectrum is a way of finding which layers/modules/weights are more important and fine tune only those. Any singular value greater than a said limit is considered signal and anything less is considered noise. The Signal to Noise Ratio (SNR) is used as a metric to determine importance.
The method outperforms QLoRA while training on only 25% layers. In fact, one can also combine the two methods. Unfortunately there aren't comparisons to LoRA or DoRA.It is a well known fact that not all layers in a network or LLM are equally important. Some layers change the input very little while some alter the input significantly. We’ve already talked about the same in one of our previous works on Mixture Of Depth Experts. So it might be natural to think, should I really update all the layers and weights when I fine tune something? The intuitive answer would be no given the context.
Now the question boils down to how does one figure out the layers to fine tune? You ideally need a metric which says how much information a layer or weight adds to the input. There are tonnes of ways to interpret matrices. The most natural way to analyse a matrix is by looking at its eigen values. Eigen values explain how much a matrix (eigen vector) modifies the said input. So eigen values are a proxy to how information rich a matrix is.
Each matrix can be represented as a product of orthogonal and a diagonal matrix called as Singular Value Decomposition. The diagonal matrix S’s elements are called singular values. Mathematically they are the square roots of eigen values. U and V are orthogonal aka UV=I (Identity matrix).
Failed to render LaTeX expression — no expression found
For large random rectangular matrices, singular values are said to obey the Marchenko–Pastur distribution. Given sufficiently large random rectangular matrix of shape (m,n), and the standard deviation σ the singular values of W are bound by
So anything which is less than these said limits can be assumed to be from noise and anything that is greater than the bound can be understood as significant enough singular values that arise from the matrix and its information itself. The code can be found here.
This gives a PSNR metric on matrices. PSNR is quite often used in Computer Vision and Image Tasks. The higher the PSNR, the higher signal is (compared to noise) indicating information denseness. So weights or modules or layers with high PSNR are “important” and contain vital information.
Given all these, you try to identify a set of layers from a network which stand higher in terms of PSNR and consider only them for fine tuning. This helps us train only those specific layers. This helps us save a lot of memory as we’d freeze the rest. Always remember, any parameter you freeze, you’d save 3x that in terms of memory if you’re using AdamW or any momentum based optimisers.

Now what does this compete against? Basically any other parameter efficient fine tuning techniques like LoRA, QLoRA and their derivatives. That is essentially what this is compared against as well. Spectrum-25% is fine tuning only 25% of the weights (the ones with highest PSNR) and Spectrum-50% is fine tuning 50% of weights.
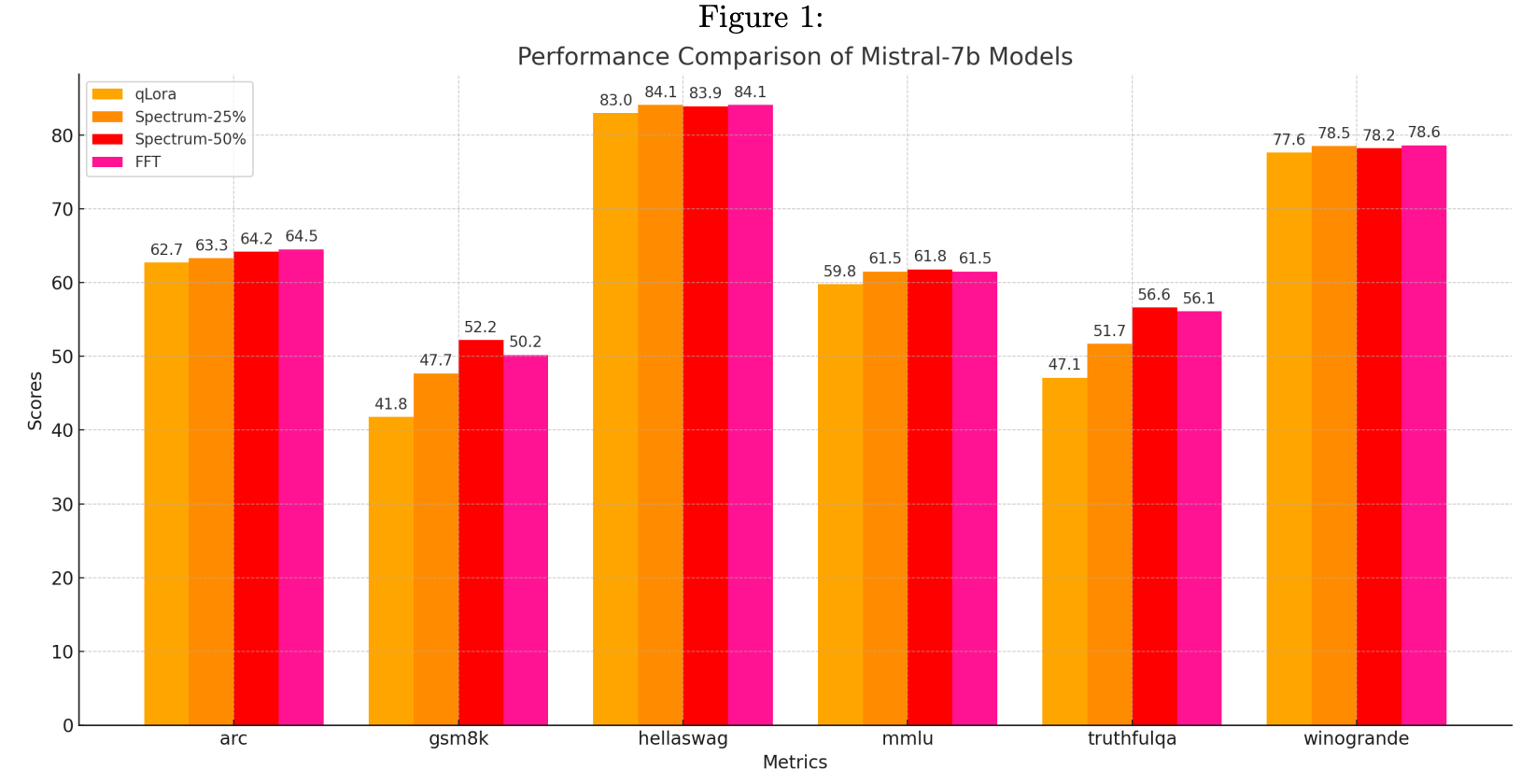
As expected, this performs better than QLoRA while being a little worse than FFT (full fine tune). But getting to those levels of accuracy with much lesser memory requirements is a good start.
This work is very similar to the works of Charles Martin at calculated content where they heavily explore Random Matrix Theory for analysing why some models are better trained than others. Do check out their wonderful content.
Learning to Reason with LLMs: OpenAI o1 models
TLDR:
OpenAI’s new o1 model, built for advanced reasoning with a "chain of thought" approach, significantly outperforms GPT-4o on reasoning-heavy tasks like math, science, and coding benchmarks. Though slower and more expensive, o1 excels in complex problem-solving by breaking tasks into steps. However, it's less suited for general, multimodal tasks where GPT-4o remains more versatile and cost-effective.
While o1 pushes AI reasoning forward, it’s not yet AGI, as it’s limited to human-documented strategies. The choice between o1 and GPT-4o depends on the task's complexity and need for logical depth.In the race to build the best models, companies like OpenAI, Meta, and Claude are competing to excel on popular benchmarks. However, recent evaluations show little improvement, largely due to the challenge of reasoning. Autoregressive models struggle with planning and executing complex tasks. While techniques like Chain of Thought prompting and tool assistance help, they fall short in many cases, making reasoning seem unsolvable—until now.
After months of teasing under "Project Strawberry," OpenAI has launched the 'o1' model, designed to prioritise thoughtful, accurate, and logical responses, even at the cost of speed. The model is trained using a large-scale Reinforcement Learning algorithm that using a “chain of thought” process, meaning they are designed to think step-by-step before responding, allowing for data-efficient learning.
The o1 family of models come in two variants: o1-preview, the preview of SoTA and o1-mini smaller and 80% cheaper model.
One of the standout features of OpenAI's o1 models is the introduction of reasoning tokens to wrap their thoughts around and break down problems and explore diverse interpretations. The reasoning is hidden from the user but billed via API(probably to stop people from training on it lol).
The context of previous inputs and outputs is retained up to a point (which in o1 models is 128k tokens). If the conversation exceeds this limit, earlier responses may be truncated to make room for new inputs and outputs.
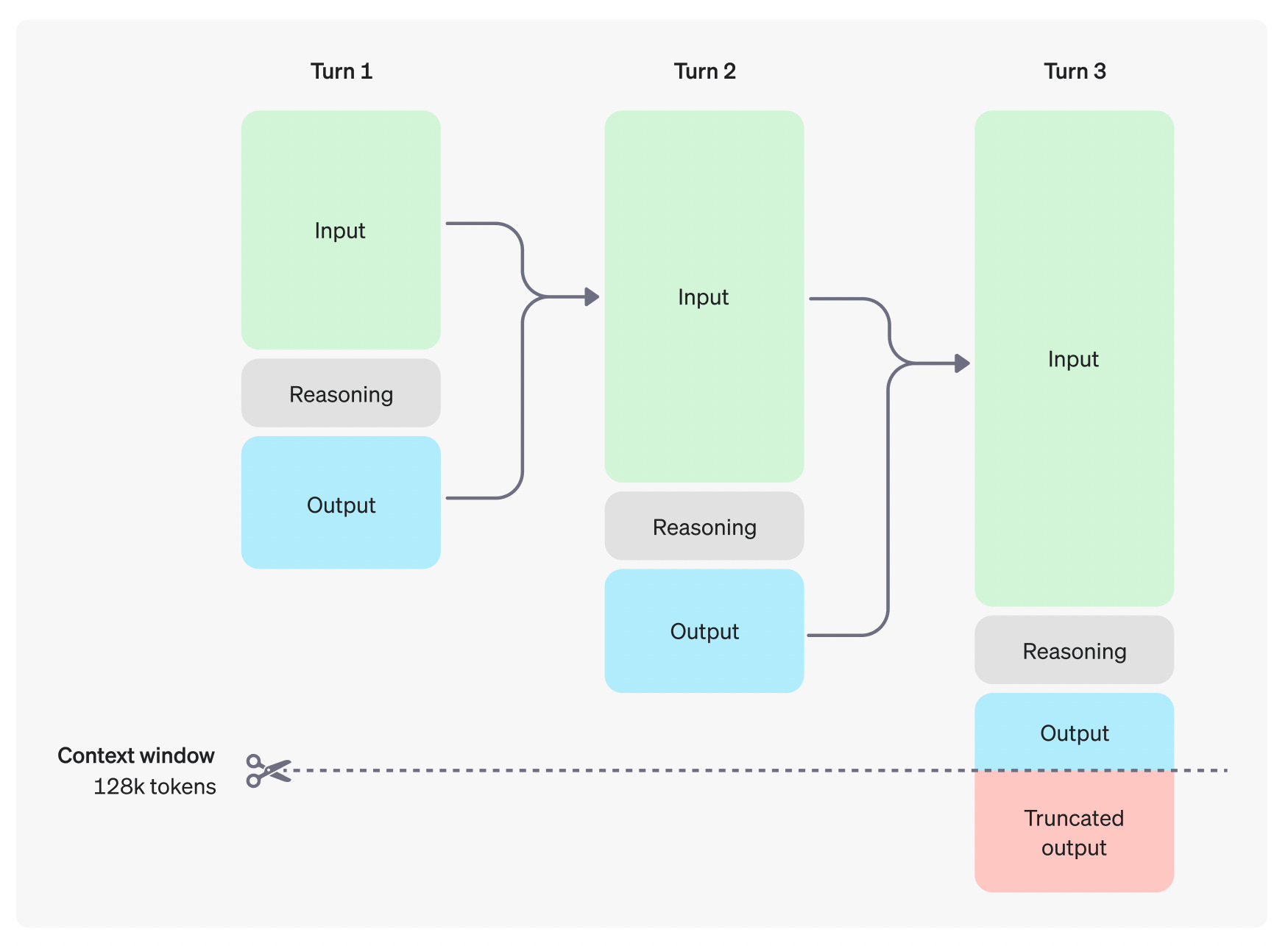
This innovation allows the o1 models to handle more complex conversations by providing answers that are not just reactive but thought out. Reasoning tokens are discarded after each interaction, ensuring that the model stays focused on relevant information.
o1 ranks in the 89th percentile on competitive programming questions (Codeforces) and has placed among the top 500 students in the US for the USA Math Olympiad (AIME) and outperforms humans on GPQA.
They found that the performance of o1 consistently improves with more reinforcement learning (train-time compute) and with more time spent thinking (test-time compute). This prompts the need for new scaling laws.

To highlight the reasoning improvements in the OpenAI o1 model, they tested it against GPT-4o on a variety of human exams ML benchmarks. Across majority of the reasoning-heavy tasks, o1 significantly outperformed GPT-4o. All evaluations used the maximal test-time compute setting unless otherwise specified.

Are we close to AGI?
Not much has been clearly mentioned on how the model has been trained but former OpenAI Chief Scientist Ilya Sutskever was part of a paper called “Let’s Verify Step by Step” which details how you could do reinforcement learning on step-by-step strategies for different problems
This is probably how o1 is trained, it tries different strategies and sees how far it can get with each path, but it also means that o1 is still limited to the strategies humanity has presented in front of it, rather than thinking of new strategies for new situations. That means it may not be considered AGI, and that it’s only good at things people have documented on how to solve. Still, that’s a pretty large number of problems the rest of the world probably could use.
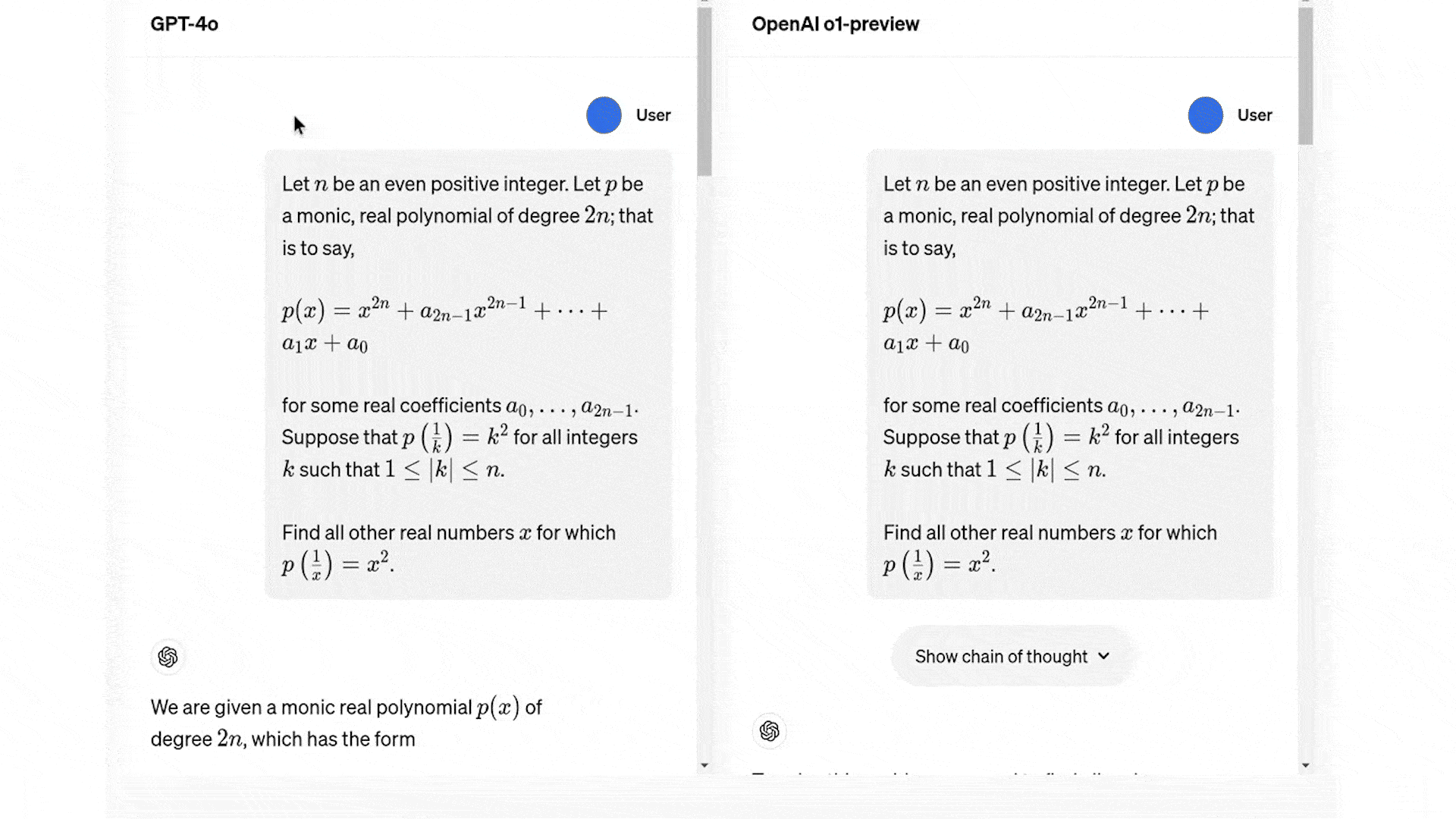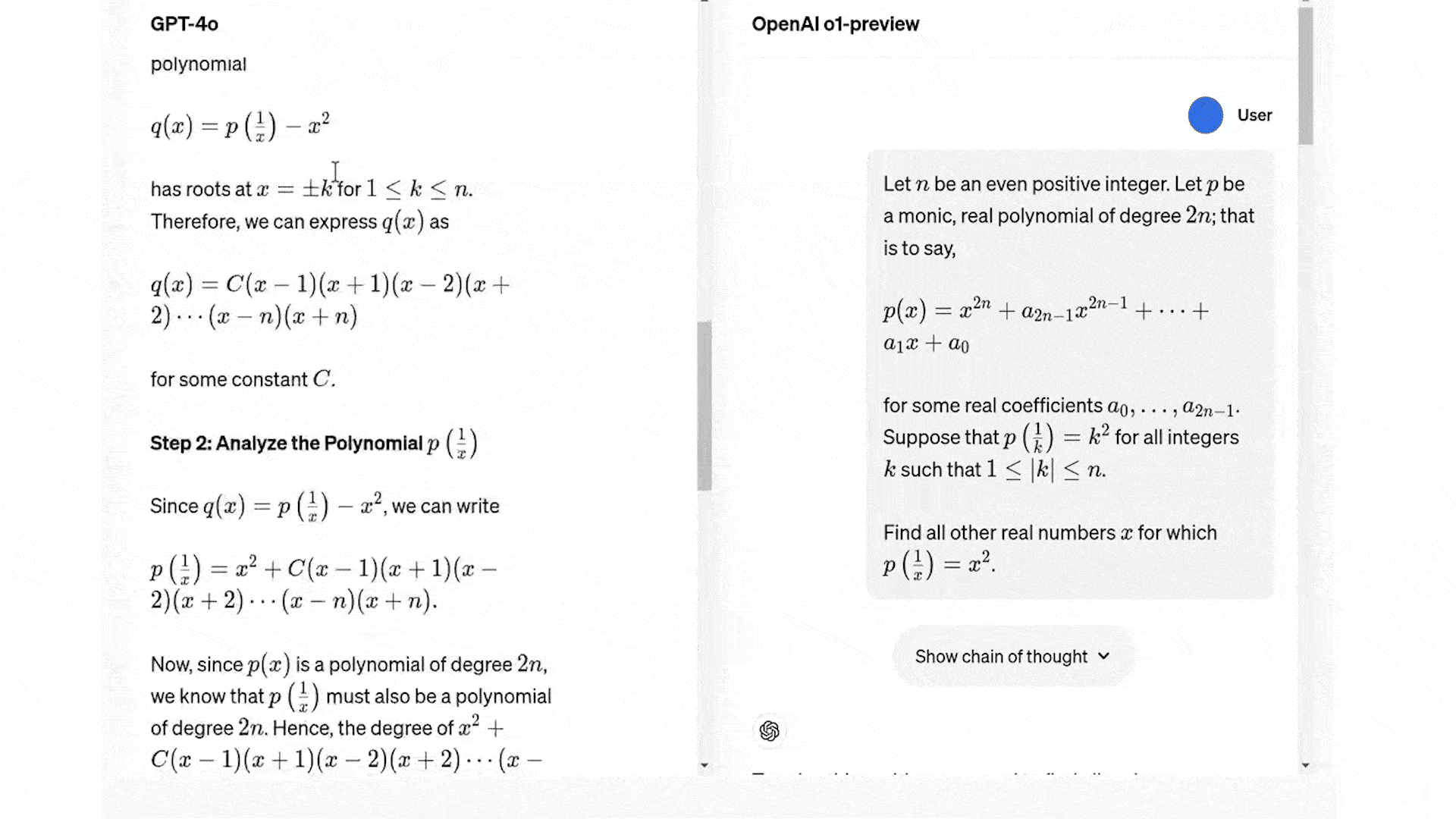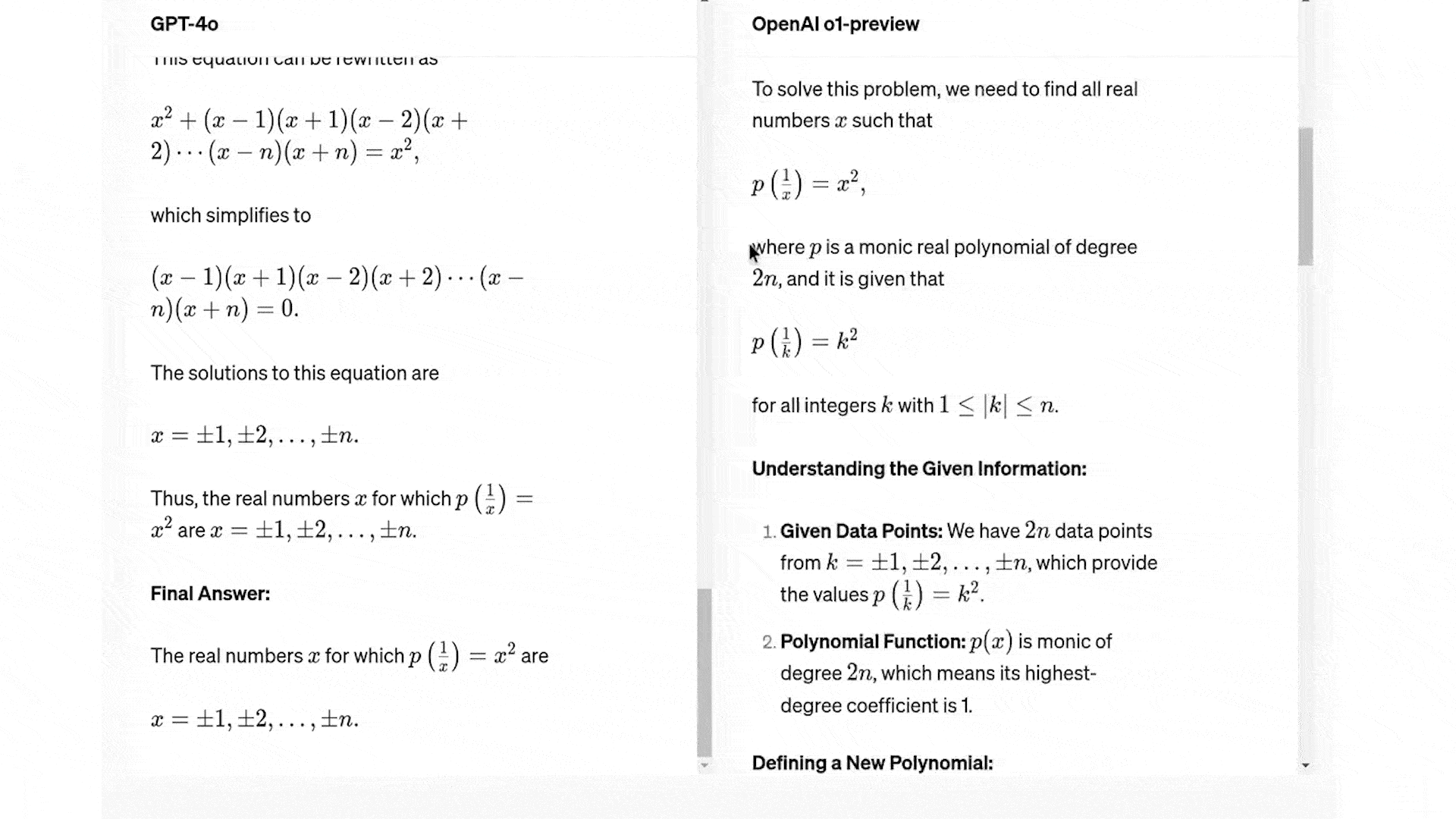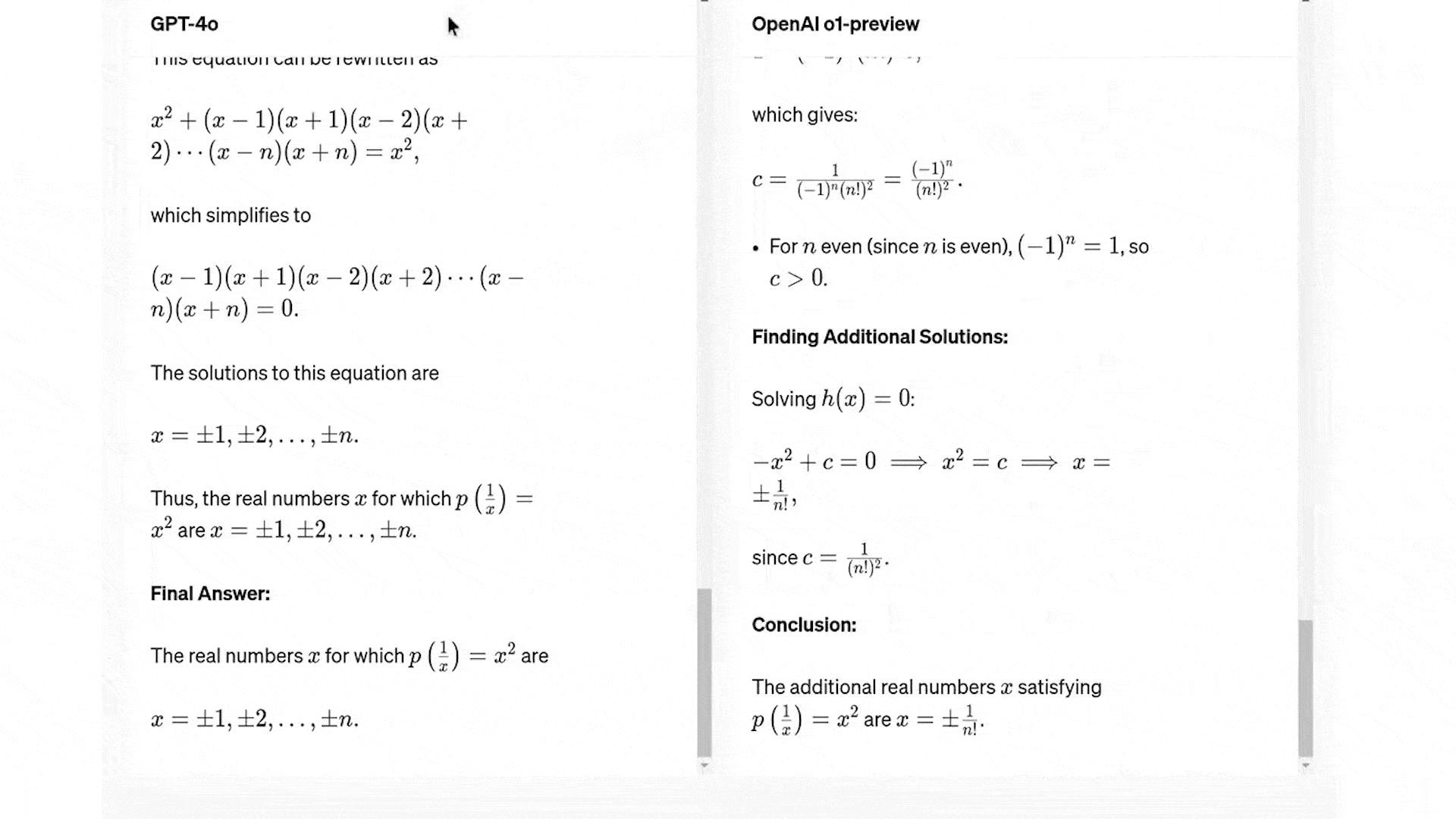
Although these benchmarks show that the o1 models can solve any complex task but that's not always the case. In the following example shown in the article by Jim Clyde Morge you can see the o1 model fails to correctly answer the question in the first attempt.

Here's an overview on where o1 vs GPT-4o model usage make sense:
The o1 model: CoT, long & complex reasoning hence Coding, Math, Science
GPT-4o is a multimodal and general-purpose tasks and speed, RAG
In conclusion, OpenAI’s O1 model represents a groundbreaking step in the evolution of AI reasoning, tackling the long-standing challenge of complex, logic-based problem-solving. While its “chain of thought” approach significantly enhances reasoning capabilities, it comes with trade-offs in speed and cost, making it less practical for everyday applications. GPT-4o, in contrast, remains the go-to model for general-purpose tasks with its versatility, speed, and cost-efficiency. The choice between O1 and GPT-4o ultimately depends on the complexity of the task and the need for deeper reasoning versus broad, multimodal functionality. The O1 model isn't perfect but the whole concept of “thinking” just came to LLMs, which is just one more step towards AGI.