

AI Unplugged 9: Infini-Attention, ORPO,
AI Unplugged 9: Infini-Attention, ORPO,
Insights over Information

Table of Contents:
Infini-Attention: Efficient Infinite Context
ORPO: Preference optimisation without reference Model
SnowFlake Arctic
What else is happening?
Infini-Attention: Leave no context behind
Context window size is a big bottleneck when it comes to LLMs. It defines the number of tokens an LLM can look at while trying to predict the next token. Over the years we’ve come from context window of 512 in BERT to 4096 in LLaMA2 to 8192 in LLaMA3 while we have 128k in GPT4, 200k in Claude 3 family and 1M in Gemini Pro. When we go towards MultiModal models and multi turn conversations with those, context window quickly becomes a bottleneck as these big sounding numbers too fall short. Even if the model supports higher context lengths, efficiency is something we can’t ignore. Each token would have its own KVs and hence memory grows pretty fast. And each new token attends to all the previous tokens hence compute blows up.
If you remember RNNs, those were not really bothered with context window because they had a vector to store all the info from the previous words in a hidden state. The problem with this is one vector might not be able to encompass the information from all the previous tokens. Transformers XL tried to address the same problem by splitting the tokens into segments and storing hidden states of the past segments. Also, while talking about Based from Together AI, we briefed about how a sliding window attention with fixed memory for all the previous tokens is a good middle ground.
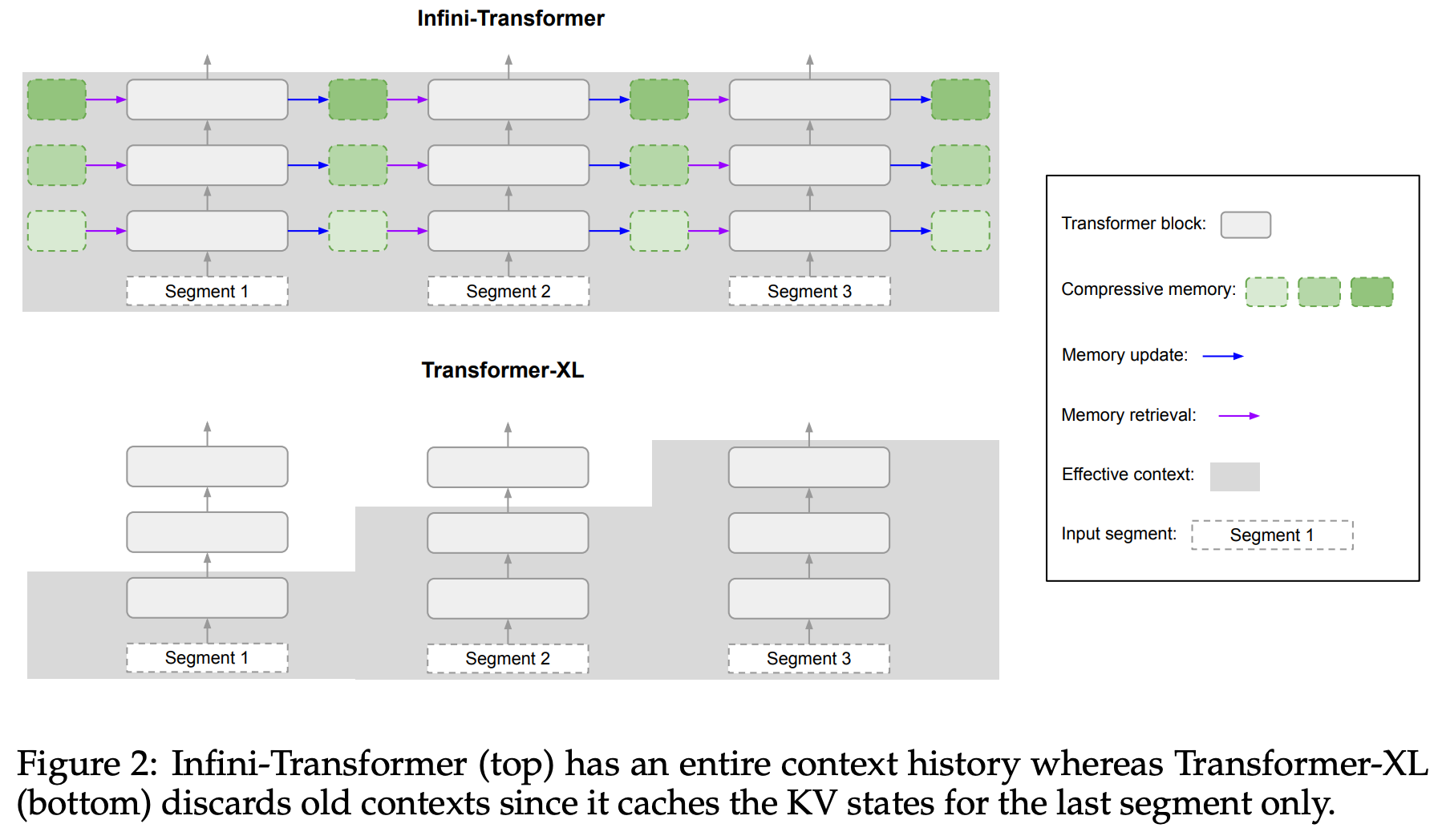
So if you see the architectural diagram below, the right half in purple is the standard attention used everywhere. This attends to everything within the context window. The left side in green is where we add memory component. This is what we use to store information from tokens that are beyond the context.

Recollect that the original Attention is formulated as where Q, K and V are query, key and value matrices obtained after multiplying the input with Wq, Wk, Wv.
A is the final attention we use and this is what is passed to the MLP layers. So there’s no change to the MLP part of the transformers. After all, its the job of the Attention heads to pass collate information selectively and pass them as features to MLP. Now how do you modify the Attention to pass information about long past tokens that are stored in memory? One way would be to add fixed size vectors (as if they’re some previous tokens) to represent compressed memory. This is something Based explores. The other way is to treat the memory computation as a separate arm and combine that with normal attention. Now the question stands, how do you calculate what weightage does it get? Simple, add them linearly with a learned parameter β. Zs is basically normalisation term.
Now addressing the elephant (cuz elephants are said to have great long term memory) in the room, how do you store, retrieve and update memory? Well we generally store KV cache, this sort of takes a leap off of that. And how do you retrieve? Well just use the queries :) basically replicating attention but with a different computation. If you expand the terms in A_mem in terms of M_s-1, you’d find a term pretty similar to attention but the non linearity, ELU+1 is applied individually to Q and K before multiplying. So assuming that memory starts with info from some tokens, which are beyond the current context, the right addend σ(Q)σ(K.t)V supplies information about current tokens so that the next set of tokens have the current ones in memory. All this comes from the paper LinearAttention where they try to reduce the complexity from quadratic in sequence length to linear in the same. And the best part is, memory doesn’t grow with increasing text length. It is of shape dkey * dval
This is like pushing things to the back of your mind, your subconscious. They exist but you don’t actively remember them. But when some thought/action triggers something and you recollect the long lost memory. Thats what query and attention is/does. There is already something in your mind right now (current context window), and one of those things (query) has triggered your brain to fetch (attention/retreival) something deep inside (memory states) for you.
And just like Multi Head Attention, one can also extend this to incorporate multiple InfiniAttention heads. In fact, one might extend this to Grouped Query Attention GQA too. But the only catch is that, a model has to be trained in this way to take advantage of it. The results from the paper look good.
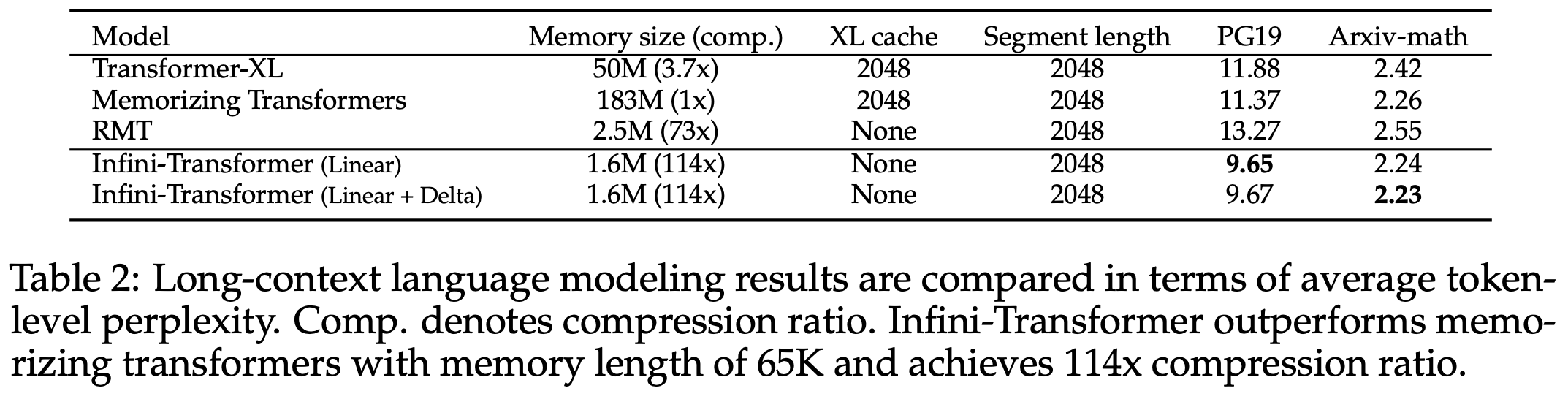
The recent Attention Mods look pretty much are taking us back to RNNs and RNN+Attention. Thus defying Attention is All you Need. The best is always in the middle. There are works like Mamba and Jamba which propose alternates to Attention/Transformers. So there’s a trifecta of SSMs (which are based off of RNNs to begin with), Transformers (which were also a mod to RNN but became standalone later) and pure RNNs. Is this the Recurrence of RecurrentNNs? :)
ORPO: Preference Optimisation
Ok, I know this isn’t something that was released last week. But around that time, we had so many other things that this skipped my attention. This is a really well written paper with cool implications so we had to feature it and so is the case with a few that follow.
LLM trainings can be ideologically separated out into three phases. Pre training, the first step is where we feed in a lot of data, asking the model to predict the next word given the context. Supervised Fine tuning (SFT) is the second step where we tune the model to specific down stream tasks, like summarisation, QnA etc etc. Chatbots have been an important downstream task for LLMs off late and when deploying LLMs as chatbots in production, it is important to make sure their output is safe, harmless and friendly. This is done in the third step called Preference Optimisation.
There are many methods to perform this. PPO is one such methodology where we have a reward model assign a score to the outputs generated by the model and fine tune on that. RLHF has been the most used technique including models like GPT. But the problem is, Reinforcement learning is not as stable to train as normal fine tunings. PPO heavily relies on techniques from RL (hence RL in RLHumanFeedback and RLAIF aka RL Artificial Intelligence feedback). There have been alternatives proposed to this. Direct Preference Optimisation (DPO) is one such, which works around the scoring mechanism of PPO, reformulates the loss in RLHF as a classification loss. This is more stable to train but falls short by a very very small. Other alternatives include Self Rewarding LLMs which ranks the output of the model by itself and filters those outputs whose score is greater than a given threshold and fine tunes on those.
The authors present an interesting observation in the paper. They train a model on Anthropic’s HH-RLHF preference data, which has chosen and rejected as pair of samples. While training, they observe that the probabilities of token in the chosen sample is not much different from the one in the rejected sample. But if you look at the samples in the data, the tokens in the first sentences are really the same, so there’s that :)
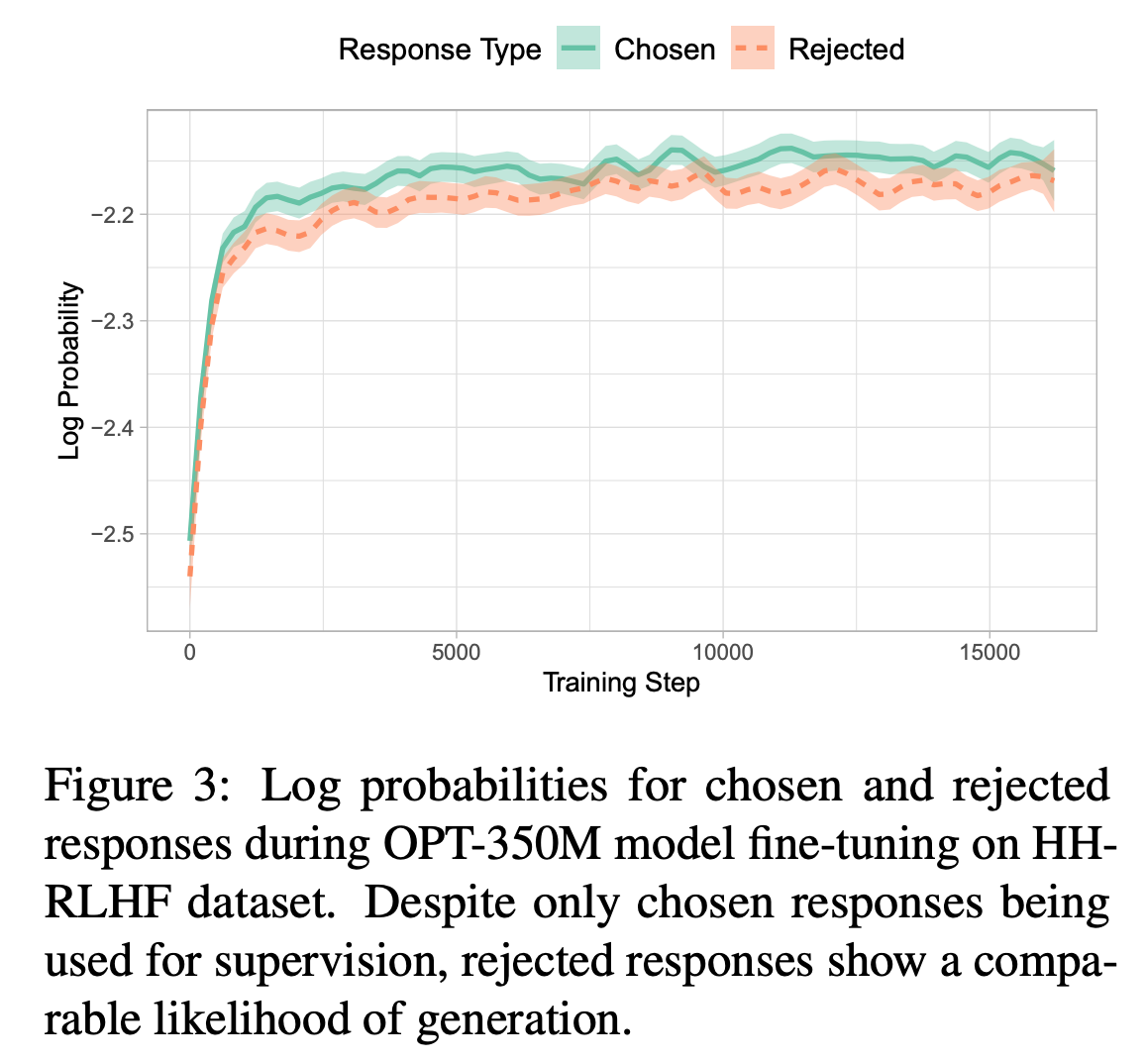
They claim that this behaviour is due to cross entropy loss. It pushes the model towards making the correct tokens to 1.0 probability but it doesn’t punish for predicting tokens that aren’t supposed to be. For example, harmful tokens are different from non-sensical harmless tokens. But Cross Entropy doesn’t squish harmful tokens fully to zero. It squishes all tokens except the winner equally. What to they propose to fix this?
Odds Ratio Preference Optimisation(ORPO) basically works with odds ratio of generating the chosen sample vs rejected sample. How to define odds ratio? Odds are basically the ratio of probability of something happening vs the same not happening.
Here Yw and Yl are chosen and rejected samples (winner and loser if you may). Now how do we use this ratio? We define a loss that takes in odds ratio as a factor and then somehow add it (linear combination as usual) to SFT loss. Note that this makes it a part of or extension of SFT rather than a separate step in itself. So its continued SFT :)
Now onto the results, they look stunning. And if you see the histogram of rewards, SFT averages around 0. Then DPO, RLHF(PPO) and ORPO push the rewards towards the positive side with ORPO doing it the farthest (on average). A testament to its success.
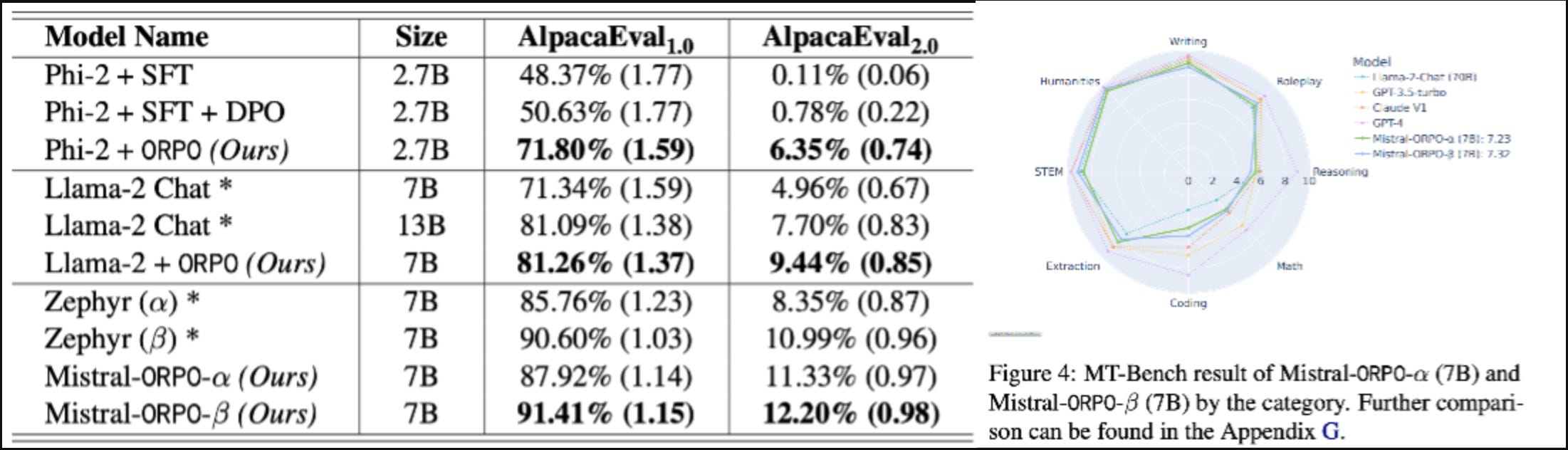
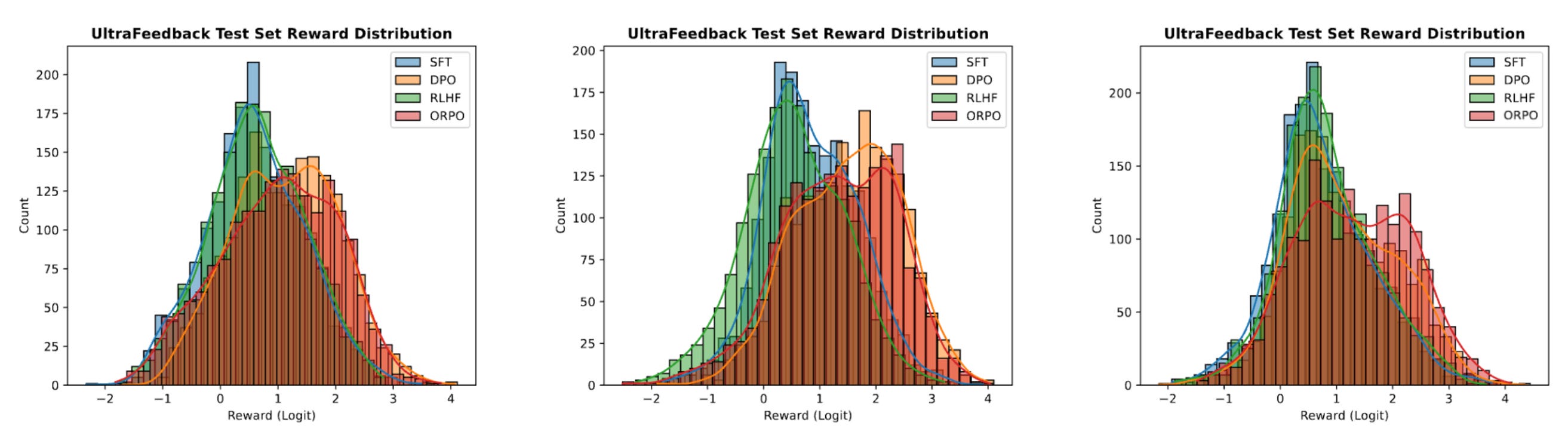
There are already quite a few fine tunes of popular models on popular datasets with ORPO.
Edit: As I’m about to publish this, I saw Yannic Kilcher release an explainer video on the same. Do give it a watch :)
SnowFlake Arctic
We have yet another addition to the list of big open source sparse Mixture of Experts models. Welcome SnowFlake arctic. It is a 480B model with 17B active parameters. Below is an architecture diagram of the same. Unlike traditional MoE, here we also have FFNN parallel to Experts. A residual* connection if I may…
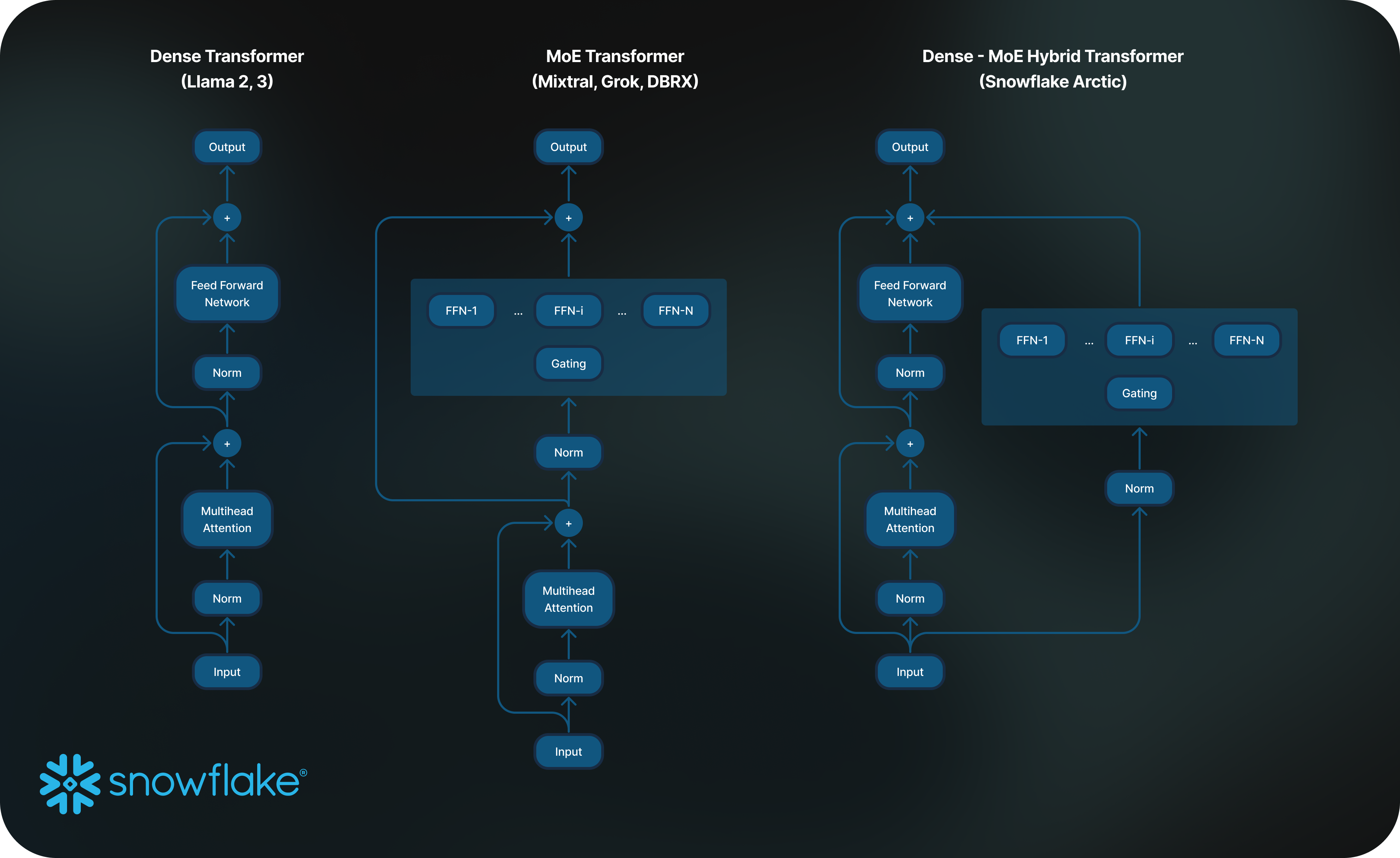
The base model is of 10B parameters and there are 128 experts each contributing 3.66B parameters in ~468B params. The advantage of having many small experts is, you’ll save a lot on inference time. There are only 2 active experts at inference. Hence it’ll take up 10B (dense) + 2x3.66B (MoE) parameters = 17B parameters. And if experts are forked off of same initial weights with some variance, then the whole MoE training can be sped up by quite a lot. But the memory requirements make it GPU Rich only :)
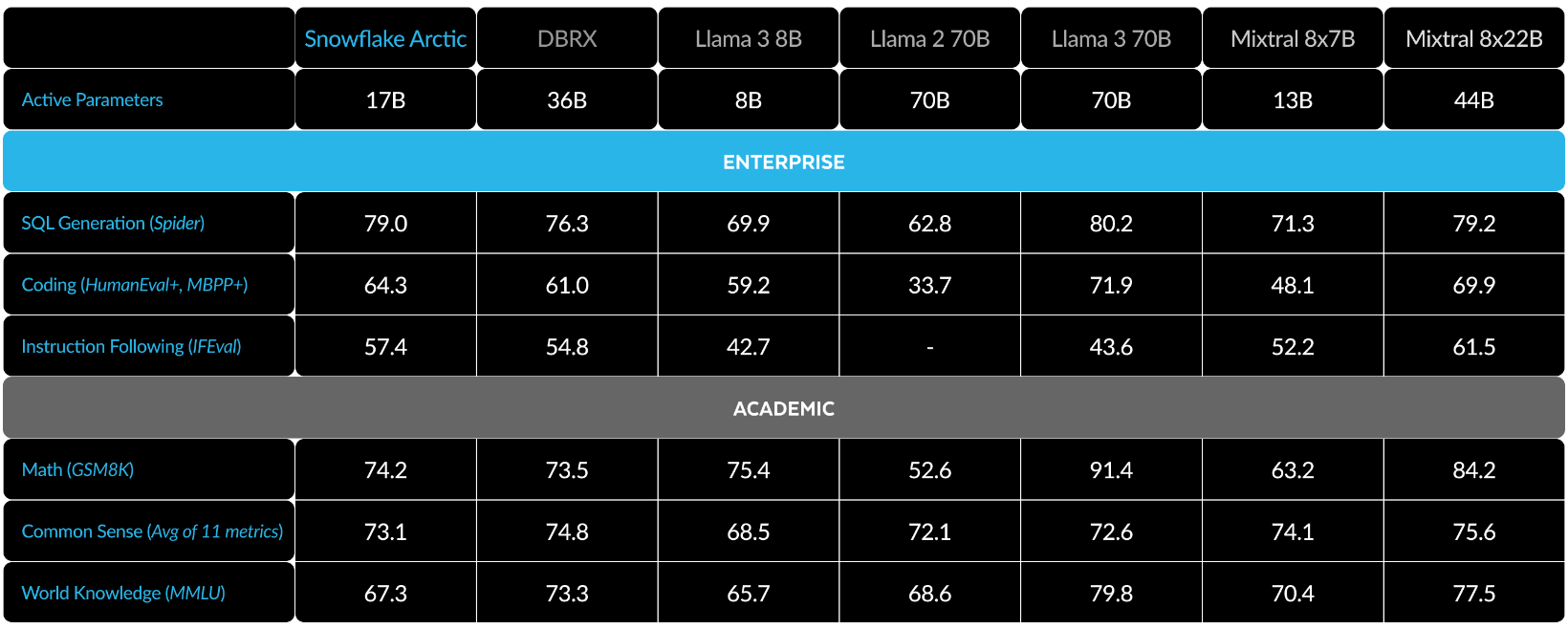
There’s also a chat/instruct variant along with the base model. They’re trained on a total of 3.5T tokens. Pretty small compared to LlaMA-3 which was trained on 15T tokens. Note that out of those 3.5T, 2.5T are enterprise focused data aka more weightage to code. The results show for it.
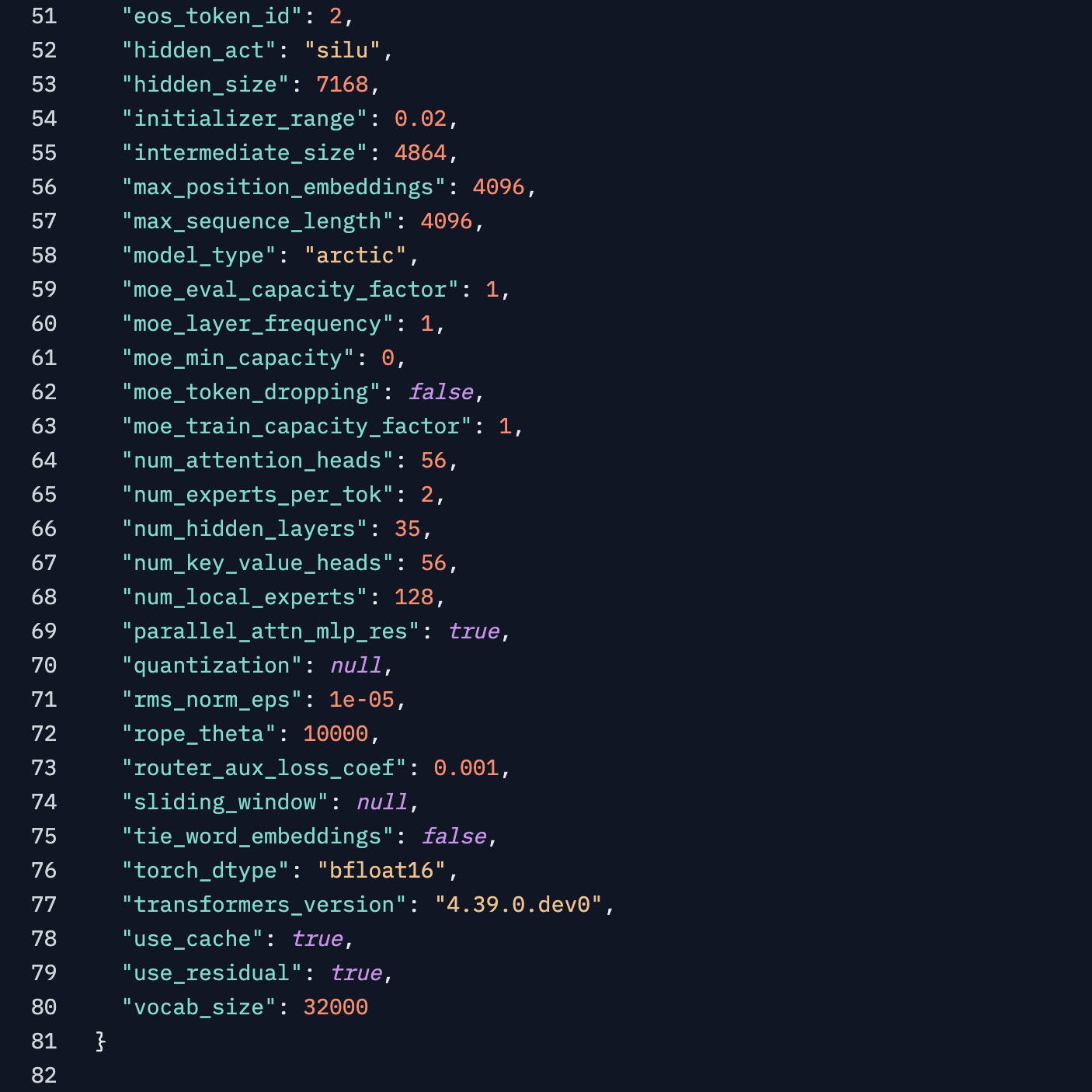
From the model config, we see that the num_key_value_heads is same as num_attention_heads which means that they’re using MHA and not GQA or MQA like the newer models. The hidden_size of 7168 makes it the widest I’ve seen in a while and there are only 35 hidden layers. Which is fine for a 10B dense model.
What else is Happening:
There are 128k and 1048k context window extensions of LLaMA3. We talked about how 8k is subpar in the modern day and age. @GradientAI’s 8B 1048k instruct model and @AbacusAI’s LlaMA3 Giraffe comes with 128k context on 70B model. I’m planning to talk about how context length extensions work in our future blogs, so stay tuned for that.
LLaVA is a fine tune of llama (and derivatives) on multimodal instruction following data. Now that LLaMA3 is out, there are fine tunes of the same. LLaVA LLaMA-3. There are also Phi-3 variants of it.
TensorRT-LLM is faster than llama.cpp as benchmarked by Jan.ai here, even on consumer GPUs.
Nvidia ChatRTX gains support to Image Search and Voice input support.
Nous research fine tuned llama3 on the hermes collection data to release Hermes-2-Pro-Llama-3-8B and it improves on llama-3 by up to 10%.