

Table of Contents:
LlaMA-3 models
Phi-3 family
Training LLMs at home Pt 2
Unsloth and LlaMA3
LlaMA3
Meta casually dropped the next generation of llama series of models. The smallest one coming in at 8B instead of the 7B we had previously for llama and llama2 families. Meta has also released a 70B model akin to llama2. Along with that, meta teased a 400B model that is under training which is GPT4 level on various benchmarks. Access to the models is gated just like llama2, but its just one request away.
To no one’s surprise, these models stand best in their size classes.

Infact, these are the results from other models for comparition and you can see the difference. MMLU of llama3 8B is on par with llama 2 70B. And to be precise, even gemma-7b is more like a 8B model. And ofcourse there are instruction tuned models to accompany the base ones.

Compared to llama2, there are a few changes in the architecture. The context length is upgraded to 8192 (8k). Though this is an increase from 4k we had earlier, this is still subpar compared to the competition. Mistral for example has 32k context length. But there are works by the community to extend the context length to higher values. While LlaMA2 7B variant doesn’t employ Grouped Query Attention (GQA), all the variants of llama3 have GQA similar to mistral and llama2-34/70B.
Another thing that changed is the template/format for instruct (previously chat) models. The format looks pretty similar to ChatML that is widely used.

You ask why llama3 performs this good? Think about what llama brought to the scene. They questioned Chinchilla optimality. They trained way beyond the chinchilla optimal of D = 20P aka data set size = 20 times the number of parameters. So for a 7B model, optimal dataset size is 20x7B = 140B params. Llama 1 was trained on 1T tokens while llama 2 was trained 1.4T tokens. This was already way beyond chinchilla optimal but chinchilla was more for training and compute optimality. LlaMa proposed that even if we overtrain the models, if it means inference performs well, we’re at profit. You can read this wonderful blog about Chinchilla's Death. Now LlaMA 3 is trained on whopping 15T tokens. Astronomically large. And Mark Zuckerberg claimed on Dwarkesh Patel’s podcast that the models continued to improve but they had to stop somewhere :)
The models also perform quite well on the LMSys chat arena leader board. 70B model scores 1210 almost reaching the likes of Claude Opus and GPT4, coming in at 5th. Llama performs better if you consider English only as it was trained mostly on english (95%). Also LlaMA3 8B comes close to Claude Haiku and CmdR while beating Mixtral Large.

LlaMA 3 is now being slowly integrated into Meta’s products like WhatsApp, Instagram and Facebook. You can also try it out at meta.ai. I couldn’t get it to work unfortunately. Maybe it is geo blocked.


The unreleased, still being trained LlaMA3 400B model is staring up GPT4 Turbo and it’ll be exciting to see how it does once the training finishes. Exciting year for open source.
Also HuggingFace was down while uploading 15T token dataset :)
Phi-3
Just when you thought Meta had this week to its name with llama3 announcement, Microsoft again throws in its hat into the ring. This time with their very own Phi-3. Phi-1, Phi-1.5 and Phi2 were significant models that stood behind the claims of High Quality data is key component to a model’s performance. It all started with the paper Textbooks are all you need last year. While the paper for Phi-3 is out, just like last year the models aren’t available on huggingface yet. Edit: The instruct variant of mini model is available on HF now.
Unlike the previous generations, this time Phi models have siblings :). There are 3 size variants namely Phi-3 mini at 3.8B params, Phi-3 small at 7B and Phi-3 medium 14B. Its good that we’re sticking to adjectives of sizes instead of Pros, Ultras and Pro Maxs.

One interesting thing I saw in the paper is a paper from Microsoft talking about benefiting Open Source :) A few years ago, this wouldn’t have been imaginable. Just how fast the night changes…

Now that Phi-3-mini was out on HF, I tried using the same config but edited the differences like embedding dimension, num_kv_heads, num_layers to find out the total number of parameters. For Phi-3-Medium, it came around 13.6B while Phi-3-Small comes around 8.6B parameters. Maybe the 7B they reported is non-embedding parameters? Mistral for reference has 7.2B total parameters. And yeah I checked llama-3-8B and it has 8.03B params :)
If you remember Phi2 was always punching above its weight (read parameter) class. It will definitely be interesting to compare the set with LlaMA3 models.
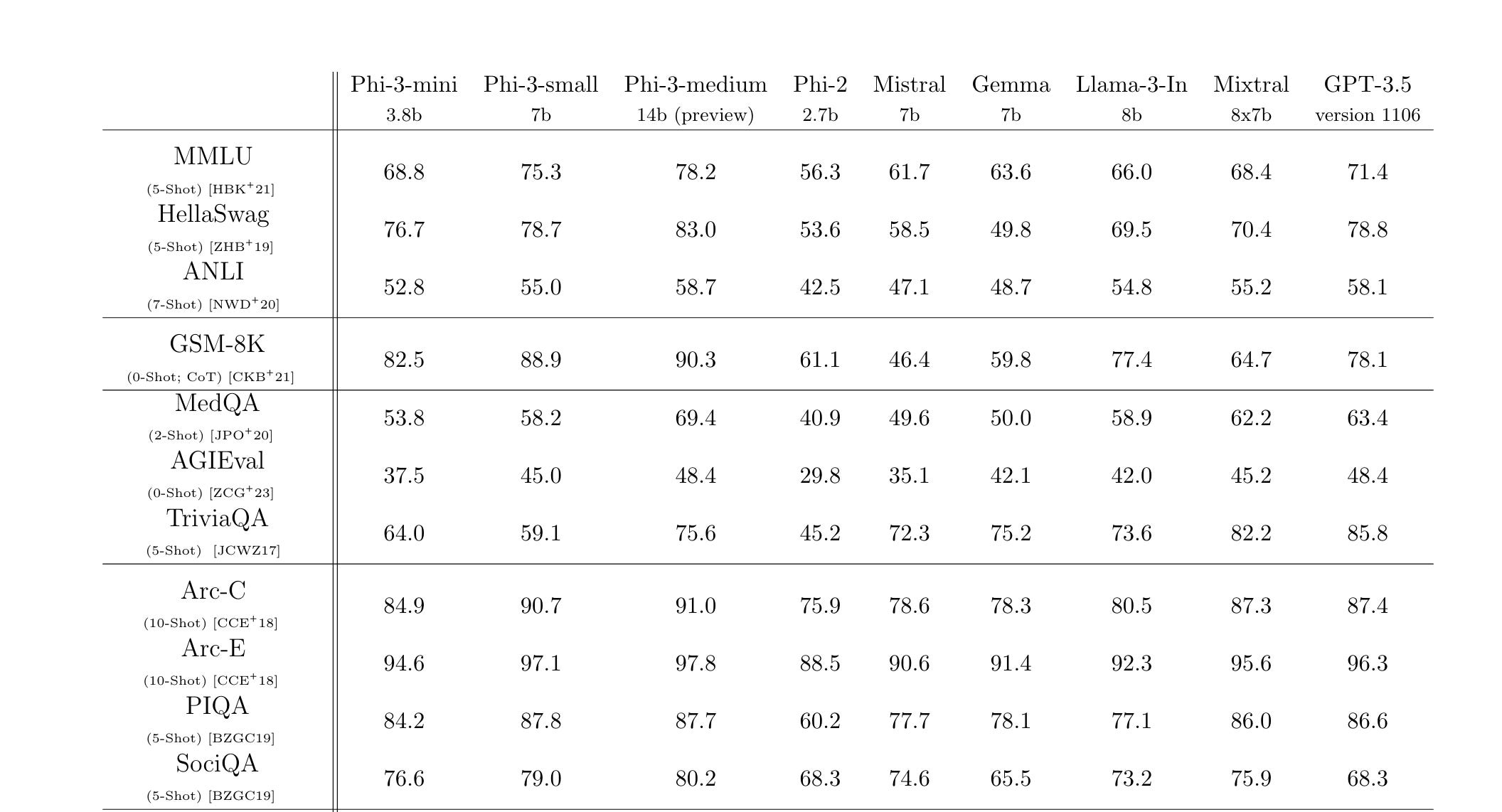
The key to LlaMA3’s success was data volume. 15T tokens to be precise. On the contrary, the key to Phi3’s success, like its predecessors’ is Data Quality. These models are trained on only 3.3T tokens for the mini model and 4.8T tokens for the small and medium models, which is ~1/5th of what LlaMA3 used.
But there’s skepticism among the community members regarding the performance of Phi models. While they do score really well on benchmarks, they seem to falter for real world use cases and perform worse than llama counterparts. I tried asking it the questions mentioned in the paper and here’s how it went.
The best part is, the model is still small enough. 3.8B at int8 would take ~4GB RAM and 4bit precision would be 2ish GB of RAM. That makes it a great fit to run on SmartPhones maybe even in the background always? :)
Training LLMs at Home Pt2 : DoRA
About a month ago, we talked about Training LLMs at home outlining this wonderful blog from answer.ai. The blog outlined how one can train(fine tune) an LLM on consumer hardware like 2x4090 with 2x24GB VRAM. For that to work, they had to implement Fully Sharded Data Parallel or FSDP for QLoRA, which loads weights in 4bit as opposed to 16/32 bit to save 4x/8x memory. LoRA already saves a lot of memory cuz in general it only trains 0.01 - 2% the number of parameters so we only track the gradients of those very few parameters (but we still have to load all params and activations in memory).
LoRA has been an incredible phenomenon in the world of fine tuning and there have been quite a few follow up works trying to improve the efficiency and performance of LoRA. One such approach is DoRA. In LoRA, you add a trainable adapter parallel to the model weights (one per weight generally) that is of low rank (typically r=8 or 16). So we train 2 matrices of sizes m*8 and 8*n and the product is added to the original m*n matrix. Thus only training r*(m+n) parameters instead of m*n (typically n~4096).
DoRA or Weight-Decomposed Low-Rank Adaptation tries to improve upon LoRA by modifying the technique in a tiny way. What the team observed was the magnitude and direction of the weight updates are synced and hence it restricts the expressive power of LoRA. They plot the correlation of the direction and magnitude for LoRA and traditional fine tuning and observe stark contrast.

Here ∇M is the change in magnitude of parameters and ∇D is the change in direction of parameters. As you see, for fine tuning there’s a negative correlation of -0.62 while for LoRA there’s significant positive correlation of 0.83. This restricts the spaces of parameters the adapter can explore. Thus restricting the capability or expressivity of the LoRA fine tunes. So they propose to treat/tune the magnitude and direction of the LoRA separately. And the resultant technique DoRA observes a negative correlation of -0.31 which is much closer to full fine tuning. And the results do speak for it. The magnitude is a vector of magnitudes of each column in the weight matrix. There are no extra trainable parameters. Hence memory footprint is on par with LoRA.

Now back to the blog, previously, answer.ai implemented FSDP QLoRA. Now its time for FSDP QDoRA. One can understand that this would be as memory efficient as the prior. What is QDoRA you ask? Just like QLoRA is quantised LoRA, QDoRA is quantised DoRA. Note that the weights of the base model are quantised. Generally the optimiser states and gradients are left at higher precision to ensure smoother gradient curves and faster convergence.

You see the loss curves and it makes sense why QDoRA matters. But train/eval loss isn’t the only metric. The improvements transfer well to downstream tasks as well. The best part is QDoRA outperforms post training quantisation after full fine tune.

Unsloth supports LlaMA3, Phi 3 soon :)
Well it ain’t a surprise anymore given the pace at which Daniel and Unsloth team iterates. They fix bugs in models. Improve training speeds and decrease memory requirements of fine tunes. Unsloth is a god send for the AI community and the GPU poor.
The speed ups compared to HuggingFace transformers is mind bogglingly insane. Though most of the speed up is for QLoRA (4bit quantised), there are incredible gains when it comes to LoRA as well (weights at 16/32bit precision).

With all the memory savings, you can fit in bigger models, larger batch sizes and longer context lengths. This will let you extend the context length of a model past its official release threshold. For example, Microsoft themselves released Phi3 mini 4k and 128k context variants.

If you ever touch fine tuning, Unsloth is a must :)