
AI Unplugged 7: Mixture of Depths, Mixtral and Mistral 22B, Reka Core, CodeGemma
Insights over information


Table of Contents:
Mixtral and Mistral 22B (8x)
Mixture of Depths
Reka Core technical report
Google CodeGemma
Schedule Free optimizer
Prompting for 10k USD
HuggingChat is now on iOS
Mixtral and Mistral 22B
Yes you read it right, Mixtral and Mistral. Mistral.ai casually dropped torrent to Mixtral 8x22B with no information whatsoever. It is yet another MoE model from the team.
Compared to Mixtral 8x7B, the hidden dimension size is increased to 6144, just like DBRX we talked about couple of weeks ago. And you notice that the newer model is both wider and deeper.

Some GPU rich have tried it out, thanks to them we have some results :). Cohere CmdR+ was touted to be the best open source model but the new mixtral quickly dethroned it.
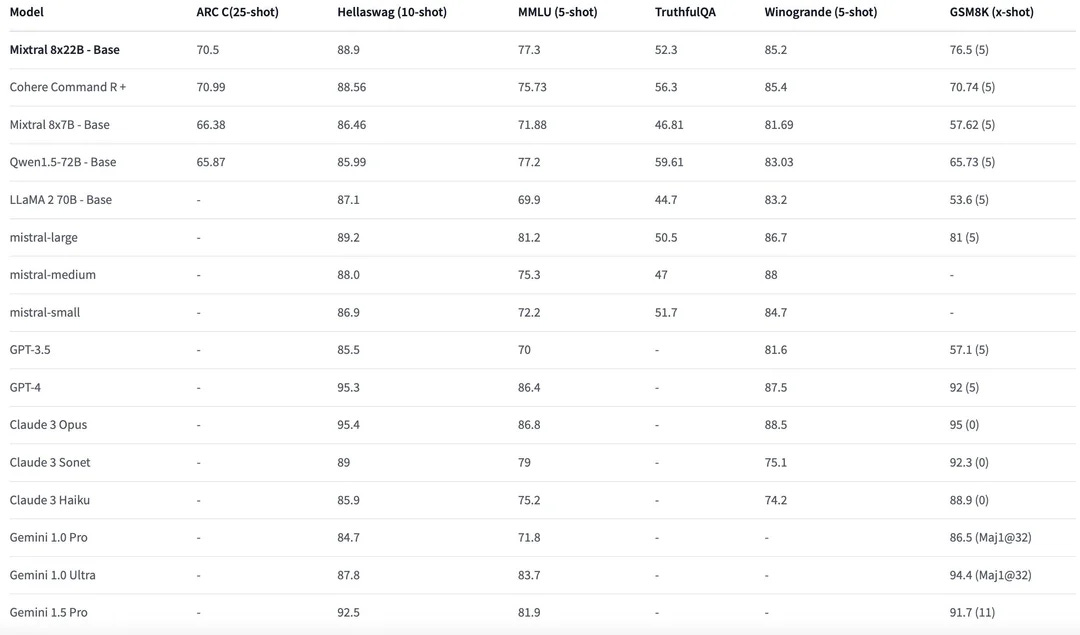
Ok as of 17 Apr, they have added a blogpost with some official benchmarks and Daniel from Unsloth updated it with numbers from Instruct variant (yes there’s one now). Also there’s now a cinema going on at twitterverse about price to perf or models :)

I tried asking it our usual pound of bricks vs kilo of feathers question. It disappointed as expected. So is it really RLHF or too much of alignment causing models to answer it wrong? Or the models extrapolating bad from the training data?

So now you might ask what is Mistral 22B when mistral.ai themselves released only an MoE model? There’s a twitter user @mejia_petit casually uploaded Mistral 22B dense model on twitter with no info (as I’m writing this) attached to it. From his other tweets, it seems like he’s fine tuning the dense model and releasing checkpoints very frequently. I tried contacting Nicolas about his approach and will update once we get any info :). There might be a paper out soon.
Update: I got to talk to him and he confirmed to me that there’s a writeup on the way. Might take a little while to get everything sorted. I’ll definitely dig into it :)
But if you ask me what makes the most sense to me is, probably taking a weighted average (probably depending on the routing probabilities) of the weights of all the experts and fine tuning them? The risk being the sum might corrupt all the learnings of each expert. But if the initial base was a dense model, like taking 8 copies of same pre trained dense model, add a routing mechanism to train MLPs separately, that would result in an easier training for MoE cuz training one small dense model is computationally easier and later you continue pre training on the MoE. This is probably what mistral.ai also did to go from Mistral 7B to Mixtral 8x7B. If one can find the similarity between weights of each of the experts, we can probably support or refute this hypothesis. Me being the mad man, did just that. There’s an average of 0.45 cosine similarity between weights of Mistral 7B and Mixtral 8x7B. Which ain’t head turning but quite significant. The interesting part however is, cosine similarity between eigen values of the weight matrices is 0.9+ which is quite astounding.

One can possibly try out other measures like Frobenius norm of the difference of the matrices or maybe the good old mean square/absolute distance. Feel free to try them out and let me know if you find something interesting :)
The HF repo mentions thanks to SliceGPT where they delete a few rows by multiplying it with a low rank orthogonal matrix to make the models compute efficient. Below is an image from sliceGPT paper. If this is anything to go by, there might have been a big matrix creating by diagonally placing all the experts, creating a sparse matrix and then multiplying it with a Q matrix to bring it down to the required dimension. Guess we’ll know soon :)

If the mechanism is open sourced, we will definitely see the same being replicated for all the available MoE models like Mixtral 8x7B, DBRX and maybe even Jamba cuz why not :)
Mixture of Depths
Transformer blocks generally have residual connections. Residual connections were introduced in ResNet for facilitating Image classification trainings. Deeper networks used to suffer from overfitting and poor generalisation. ResNet with its Residual connections solved this issue by letting the networks learn only the delta to be applied to the input. So instead of y = f(x) we have y = x + f(x) where f(x) is the output of a layer in the network. With the initialisations of layers generally being around zero, this makes sure that upon initialisation, a layer doesn’t reset the information output by the previous layer but adds on to it.
If you observe closely, you’d notice that the output across a few consecutive layers is pretty much similar. In fact, I was experimenting with the same a couple of months ago for llama2 13B and here’s what I found

As you see there’s a very high correlation between outputs separated by few layers. And for example, I observed a 0.85 correlation between outputs of layer 25 and layer 35 in llama2 13B (which has 42 total layers). So if you skip those 10 layers (with a little fine tuning to compensate), your inference would be 20-25% faster. If the layers are static (meaning if you skip same layers every time) you don’t even need to load those layers (though this might not be a likely scenario). Also, the distance between two vectors is very low. This is very likely an artefact of residual connections and weight init.

Armed with this knowledge, one would naturally explore if we can skip some layers in the network. I was exploring the same. This is exactly what folks at Deepmind did in the paper. But the paper looks at it from a little different angle. They choose to skip passing a few tokens to the layer. So if you just zoom in to that layer, if we skip say half the tokens, we only perform QxK multiplication on half the tokens resulting to 1/4th compute (for that layer, compared to passing all tokens).
Now the key query to be asked is, how do you choose which token goes where? If you let the token choose whether to go through, called Token Choice Routing, a layer or around it, it might lead to load imbalance where all tokens might choose the same/similar path (aka skipping same few layers). Mixture of Experts (MoEs) too have the same problem and they generally solve it by adding Auxiliary load balancing loss. The other routing mechanism, called Expert Choice Routing, is to calculate the probabilities of a token needing to go through the layer (aka doing the compute of that layer) for all the tokens, and choose the top-k among them. This ensures that compute per layer is fixed.
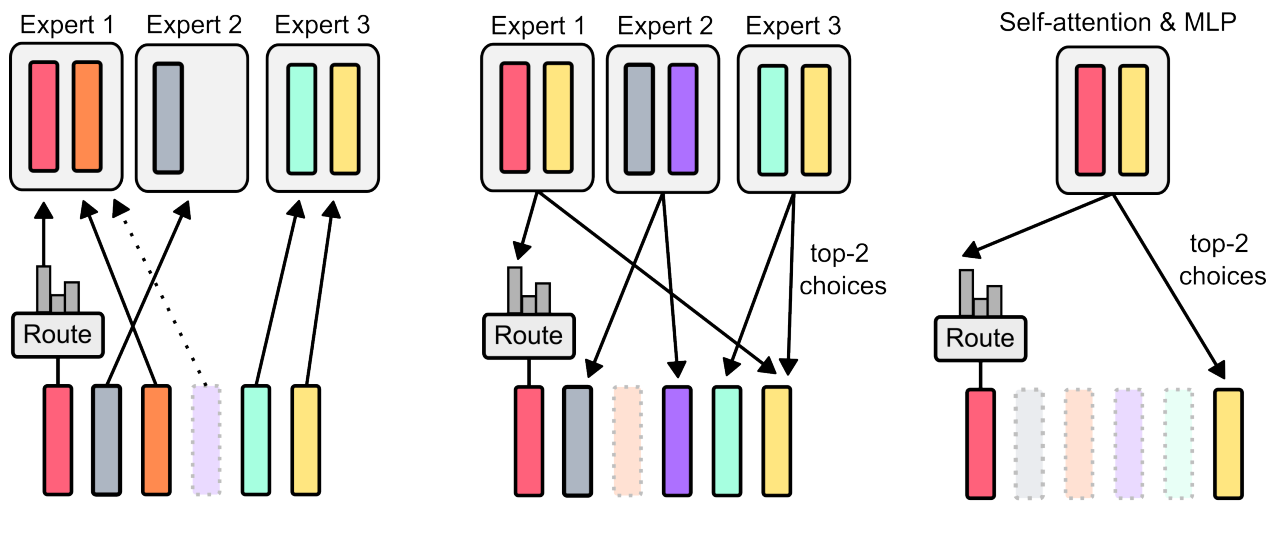
So given the same compute budget, Mixture of Depths (MoD) outperforms baseline transformer network. And the optimal loss of MoD is lower than that off the dense one. Also they observed that routing around every other block is crucial for performance.

One might wonder, what if we mix MoE with MoD. The authors also present something called MoDE, Mixture of Depth Experts which does exactly this. And the benefits compound (yay!). Unfortunately, there’s no comparison of MoE vs MoD.

An amazingly interesting work. One thing I’d love to see is the comparison between routing across every layer vs every other layer (aka for every other layer, we don’t skip). One other thing is to see what happens if we skip a layer for all the tokens instead of skipping tokens for a layer (the one I mentioned initially).
Reka Core Flash and Edge: Technical report
In one of our earliest editions, we briefly looked at Reka Flash and Edge. It looked quite interesting. It even answered the pound of bricks vs kilo of feathers correctly. These are pre trained on multiple languages including Indian ones like Telugu, with support for . Add to it that these models are multimodal with Encoder Decoder architecture making it an interesting read. There wasn’t much info at that time but now they released a technical report, presenting us with a wonderful opportunity to dig deep. I also recommend you to checkout YiTay’s blog about training models as a small company.

From the previous announcement, they improved Reka Flah by a fair margin and Reka Core is still under training yet packs a punch compared to the likes of GPT4 and Claude 3 Opus.

One interesting thing they try is to rank model’s output using another model, Reka Core in this case. They observe that the outputs closely match Human ratings. This opens up an interesting paradigm. Once the models are smart enough, we can rank the outputs using models themselves. Remember that discrimination and ranking is easier task to solve than generation (the key idea behind GANs). One can add a parallel leaderboard to the LMSys Chat Arena but ranked by big and capable models, probably those with Human ranking elo of 1150? Now expanding this further, if you ignore the compute required, we can evaluate LLMs in an automated way. I strongly believe that an automated eval environment is a key to super human performance. Look at AlphaZero or AlphaGo for example.

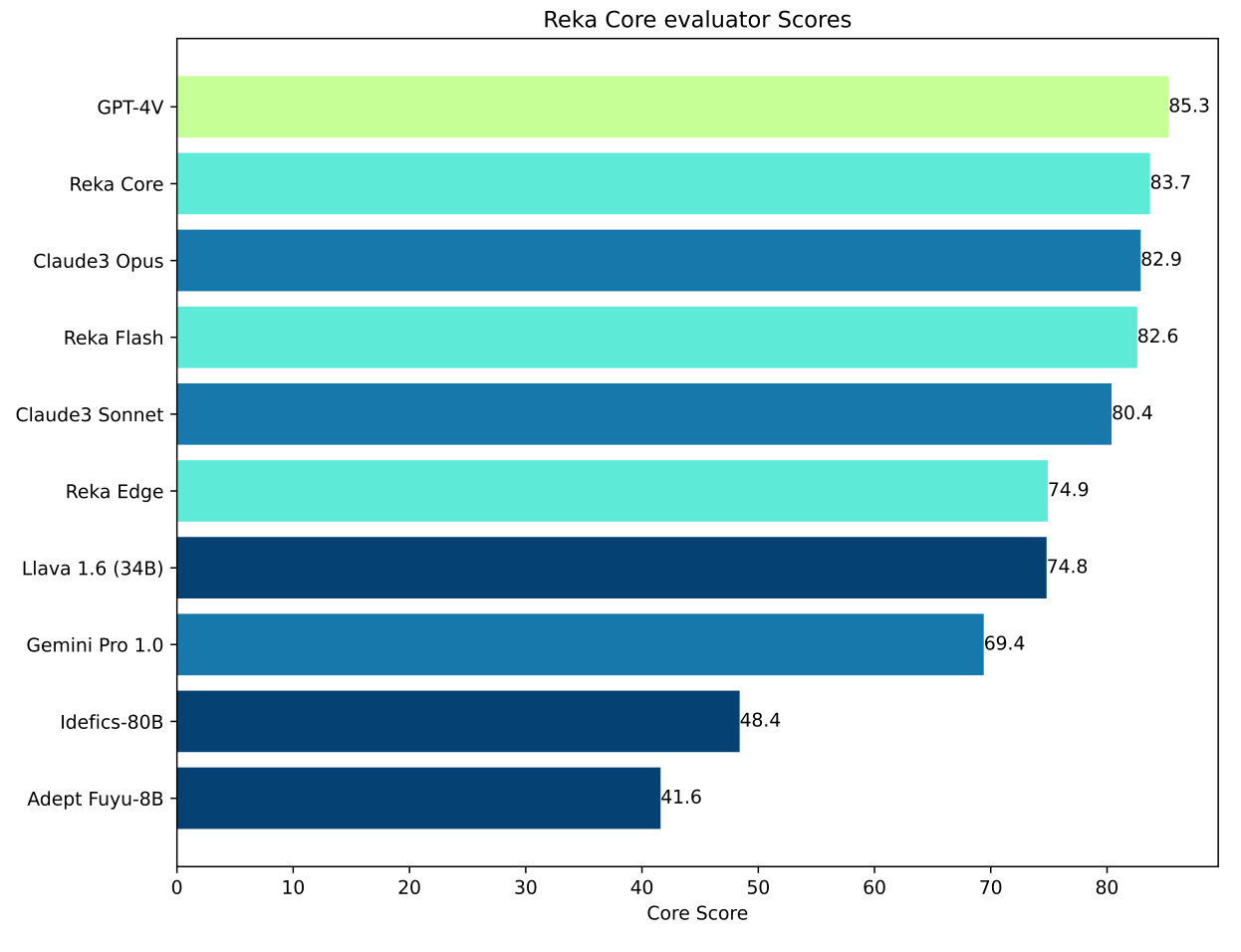
Reka Edge is a 7B model akin to llama and mistral 7B and seems to significantly outperform them. Reka Flash is a 21B model that seems to outperform Mistral medium, Llama2 70B and Gemini Pro 1.5.

Unfortunately, the paper doesn’t provide much information about architecture or training details or etc. What a shame huh!
Google CodeGemma
Google recently released CodeGemma, a code variant of the Gemma family of open models. The only difference I see in the architecture is, codegemma seems to use approx gelu. If you recall correctly, there were bugs in the gemma implementation causing 7B to perform poorly, so much so that it was underperforming 2B variant in some tasks. Daniel from Unsloth swiftly fixed the bugs though. There hasn’t been any evidence yet of the same being the case with codegemma thankfully. We’ve talked about Gemma family of models in one of our previous editions, do take a look :)
Schedule Free Optimiser
If you ever trained or fine tuned any model, you’d know that there’s a problem of choice when it comes to choosing an learning rate schedule. A good schedule can go a long way. Off late, cosine scheduling has been sought after. And if my memory serves me right, even the Attention is all you need paper employed a linear warmup before the original schedule. In linear warmup, you increase the learning rate from a small value till the initial learning rate you set for some few steps at the start of training to make sure we don’t do drastic changes to the weights at the start.
The problem now is, people have come up with various schedules like cosine, cosine with annealing, linear decay etc etc. Choice is sometimes a problem. If only there was one schedule to rule them all…
With schedule free optimisers, there is no need to tweak the schedule. You only set the initial learning rate and chill. This is how the update looks like.

People have tried this optimiser and reported better results on twitter. Looks at the retweets by Aaron. It has swiftly been integrated into torch, huggingface and all.
Prompting FTW
There was a tweet (yeah I refuse to call it X/Post) challenging people to make solve a reasoning and pattern simplification problem with an added incentive of 10k$ for anyone who could come up with a prompting solution to solve this

The problem looks quite simple. You just identify one of the four problems and simplify it. If one can write code, this is simple to solve. Something an automata would be able to solve too. But remember, tokenisation plays a very key role in this. Also, one has to make sure that the model accurately follows the answer format. And if the model hallucinates or makes a mistake on one token, then we’re basically out of luck and the solutions turns wrong.
I’d highly advise you to give it a try to prompt the model to solve it. You can generate random examples and run a small piece of code to get Input Output pairs to evaluate yourself. Once you’re done trying, if you’re curious what prompt was able to achieve 90% success rate (on 50 examples), here’s the tweet from the winner explaining their approach.
Here’s a gist outlining their prompt. If you look closely, in the rules, instead of mentioning only the four steps as the above screenshot, here the author outlines every possible input output pairs. The reason why you see RULE:#A #A → #A in line 24 is the author checks 2 items at once, then moves onto the next token. There are few shot examples describing the approach making the model understand what is expected and how it is to be done. And to end things, there’s a cash reward for the model for it to perform better :)
Out of curiosity, I tried my hands at the same in a slightly different way. I wrote a python program and asked the models to emulate the output only by dry running aka not executing the code in sandbox environments the models have access to. Though I was trying the free models like ChatGPT-3.5, Microsoft Copilot (GPT-4), DBRX instruct, Cohere CmdR plus, Mixtral 8x7B instruct the results were underwhelming. In fact, all of them got it wrong on the first iteration itself. Then I tried adding more print statements elaborating each step hoping it’d help. Here’s the results: ChatGPT3.5, Cohere CmdR Plus, Mixtral 8x7B Instruct. Unfortunately not much improvement. Can probably improve the prompt but I’ll leave it for you guys to try :)
HuggingChat iOS
HuggingChat is now available on iOS App store. I use HuggingChat regularly to try out models like Mixtral, Cohere CmdR etc etc. The best part is, it has access to the internet. So you’re not restricted by the models’ knowledge cut off dates and less chance of it hallucinating. Give it a try :)
 | A guest post by
|